Glass - 最新版
Glass是一个隐形桌面助手,能够实时捕捉屏幕活动和音频内容,理解上下文,并将其自动转化为结构化的知识资产。

VideoCaptioner是一款功能强大且易于使用的视频字幕处理工具。它不仅支持语音识别、字幕优化和翻译全流程处理,还提供了丰富的配置选项,满足不同用户的需求。
57MB35 人已下载 手机查看
![卡卡字幕助手(VideoCaptioner)的使用截图[1]](https://pic.sd114.wiki/wp-content/uploads/2025/04/1743788423-1743788423-VideoCaptioner-2.webp)
如果你还在为视频字幕的生成、优化和翻译烦恼,那么VideoCaptioner(卡卡字幕助手)绝对值得一试!这是一款基于大语言模型(LLM)的视频字幕处理工具,支持语音识别、字幕断句、优化、翻译全流程处理,操作简单,无需高配置,无论是小白用户还是专业人士都能轻松上手。

支持国内外主流视频平台(B站、Youtube、小红书、TikTok、X、西瓜视频、抖音等),自动提取视频原有字幕处理。如果需要下载受限制的视频,可以通过配置Cookie来获取登录信息,确保下载高质量视频。
VideoCaptioner支持多种语音识别方式,包括在线接口和本地离线模型,用户可以根据需求灵活选择。
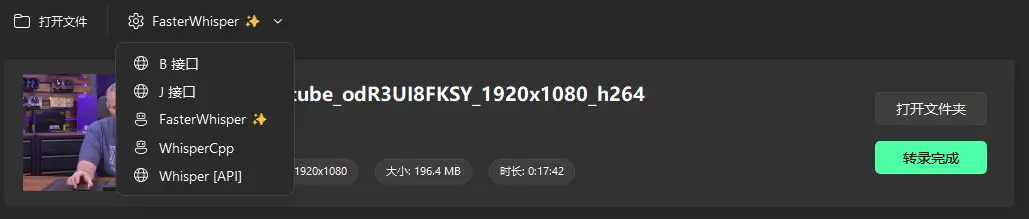
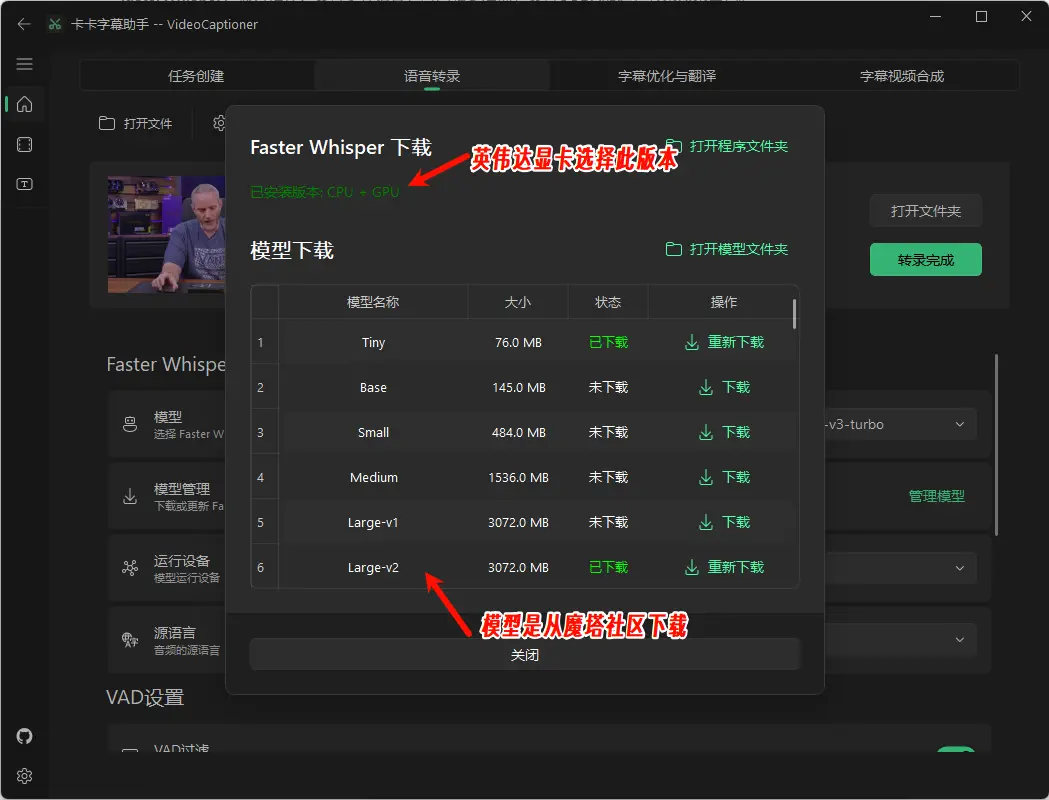
Whisper 版本有 WhisperCpp 和 fasterWhisper(推荐) 两种,后者效果更好,都需要自行在软件内下载模型。注:以上模型国内网络可直接在软件内下载,本人测试确定是从魔塔社区下载,速度很快。
| 模型 | 磁盘空间 | 内存占用 | 说明 |
|---|---|---|---|
| Tiny | 75 MiB | ~273 MB | 转录很一般,仅用于测试 |
| Small | 466 MiB | ~852 MB | 英文识别效果已经不错 |
| Medium | 1.5 GiB | ~2.1 GB | 中文识别建议至少使用此版本 |
| Large-v2 👍 | 2.9 GiB | ~3.9 GB | 效果好,配置允许情况推荐使用 |
| Large-v3 | 2.9 GiB | ~3.9 GB | 社区反馈可能会出现幻觉/字幕重复问题 |
| Large-v3-turbo👍 | 1.6 GiB | ~1.9 GB | 效果号,速度快,推荐使用 |
推荐模型: Large-v2 和Large-v3-turbo稳定且质量较好。
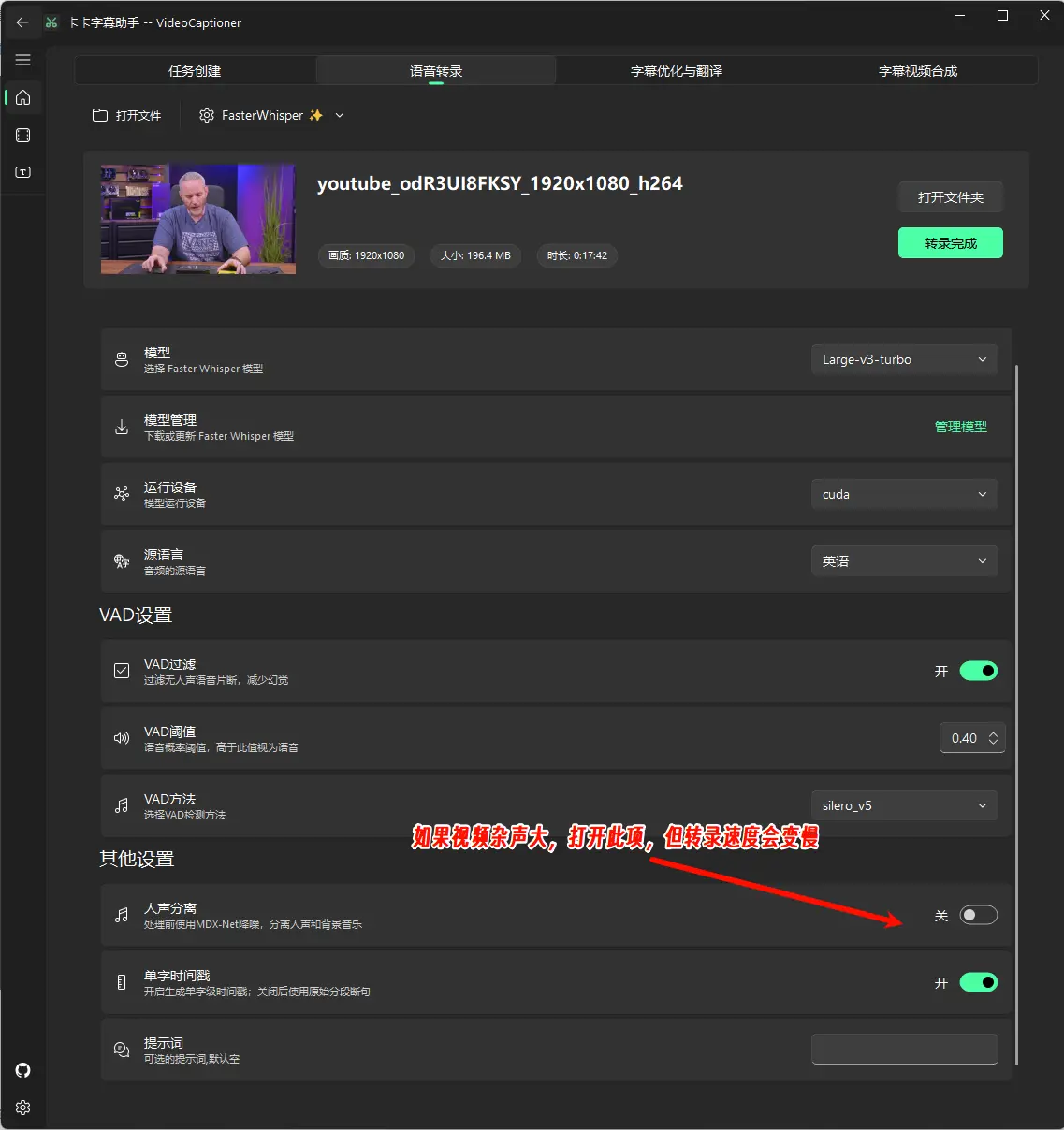
VAD过滤:开启后,VAD(语音活动检测)将过滤无人声的语音片段,从而减少幻觉现象。建议保持默认开启状态。如果不懂,其他VAD选项建议直接保持默认即可。
音频分离:开启后,使用MDX-Net进行降噪处理,能够有效分离人声和背景音乐,从而提升音频质量。建议只在嘈杂的视频中开启。
VideoCaptioner利用LLM的强大能力,对生成的字幕进行智能优化和翻译。
| 配置项 | 说明 |
|---|---|
| LLM 大模型翻译 | 🌟 翻译质量最好的选择。使用 AI 大模型进行翻译,能更好理解上下文,翻译更自然。需要在设置中配置 LLM API(比如 OpenAI、DeepSeek 等) |
| DeepLx 翻译 | 翻译较可靠。基于 DeepL 翻译, 需要要配置自己的后端接口。 |
| 微软翻译 | 使用微软的翻译服务, 速度非常快 |
| 谷歌翻译 | 谷歌的翻译服务,速度快,但需要能访问谷歌的网络环境 |
推荐使用 LLM 大模型翻译 ,翻译质量最好。
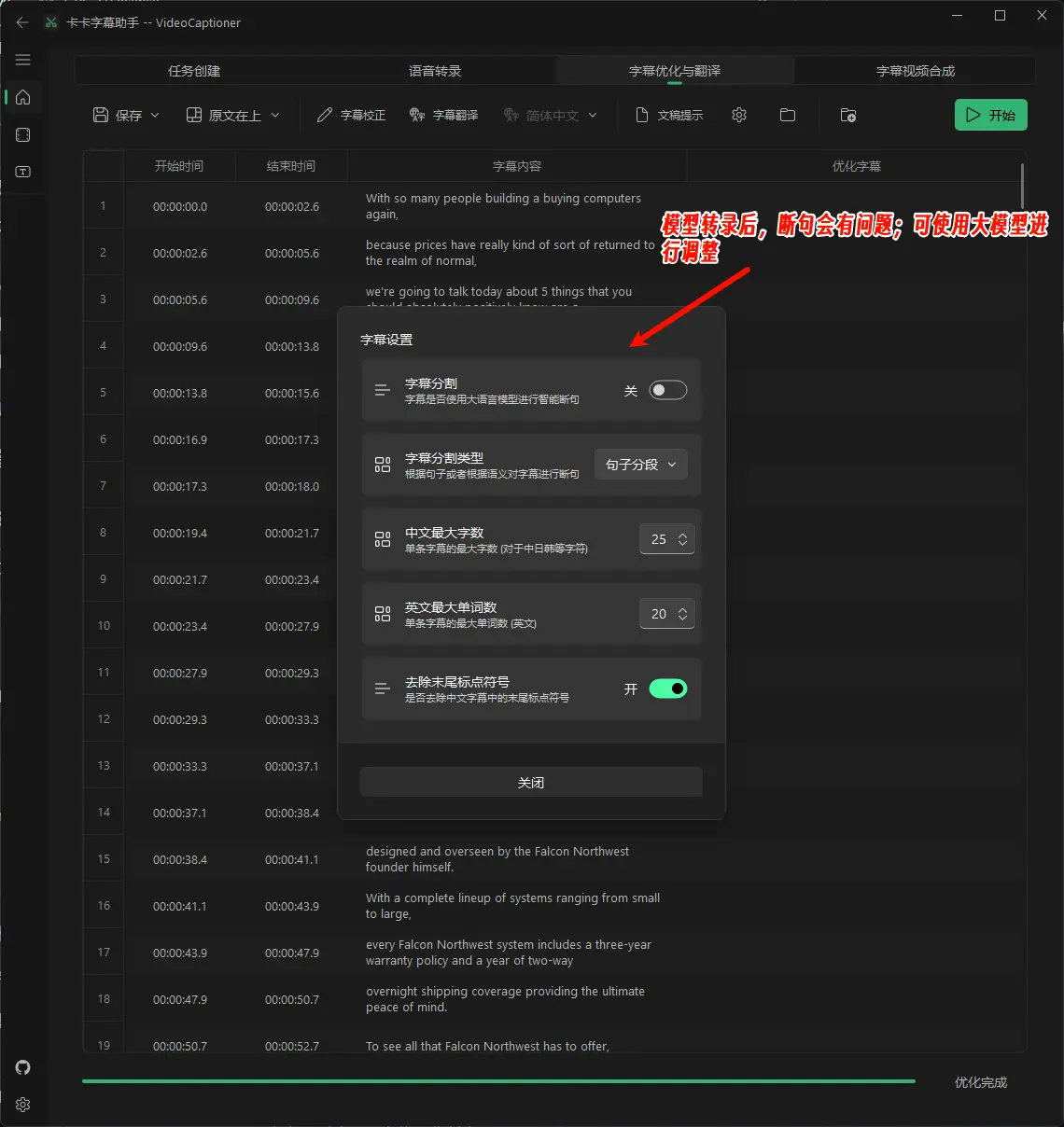
智能断句:开启后,全流程处理时生成字级时间戳,然后通过LLM大模型进行断句,从而在视频有更完美的观看体验。有按照句子断句和按照语义断句两种模式。可根据自己的需求配置。
字幕校正:开启后,会通过LLM大模型对字幕内容进行校正(如:英文单词大小写、标点符号、错别字、数学公式和代码的格式等),提升字幕的质量。
反思翻译:开启后,会通过LLM大模型进行反思翻译,提升翻译的质量。相应的会增加请求的时间和消耗的Token。(选项在 设置页-LLM大模型翻译-反思翻译 中开启。)
文稿提示:填写后,这部分也将作为提示词发送给大模型,辅助字幕优化和翻译。
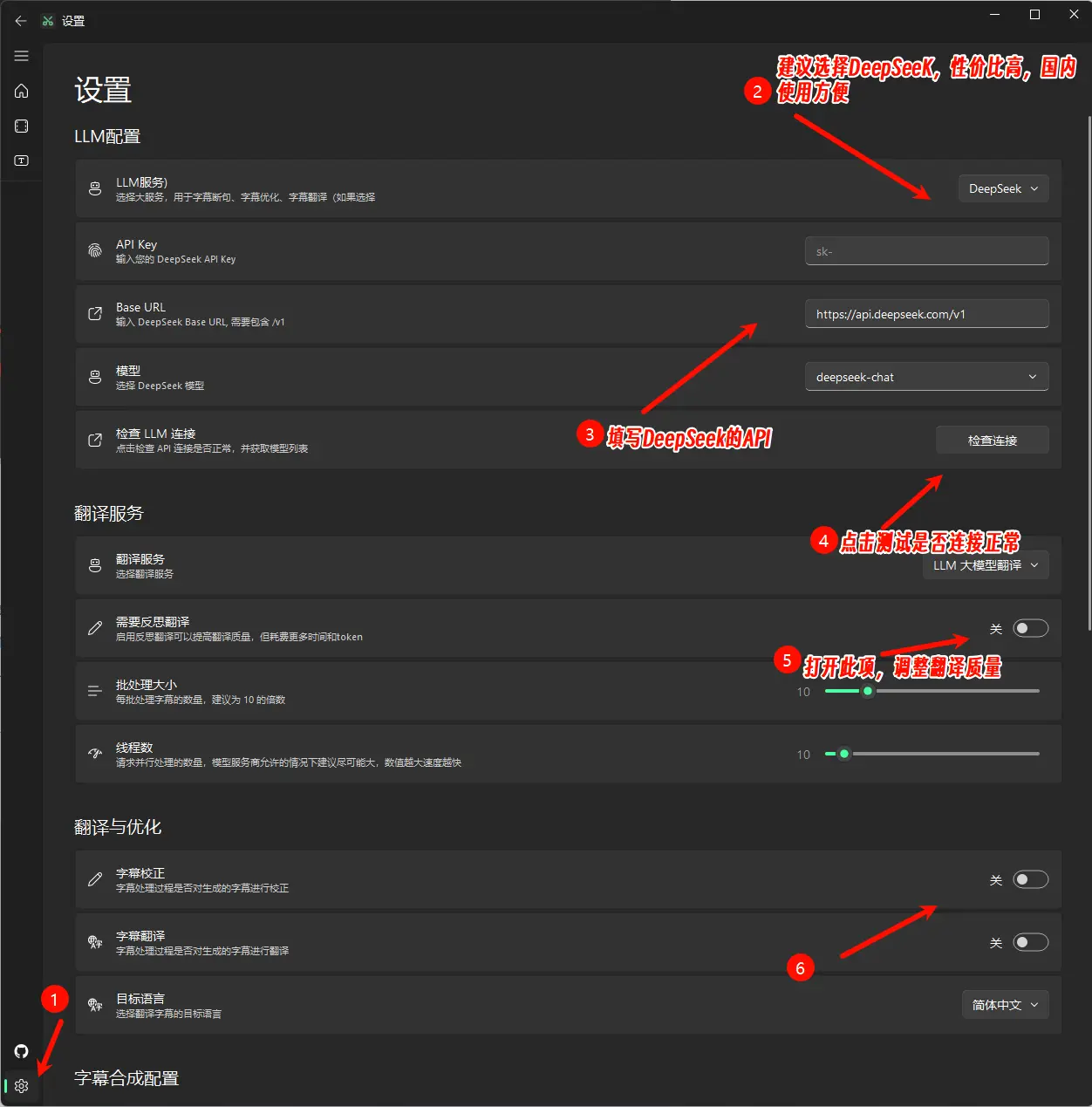
LLM 大模型是用来字幕段句、字幕优化、以及字幕翻译(如果选择了LLM 大模型翻译),建议使用DeepSeek进行翻译,准确率较高,价格低,性价比十足。
| 配置项 | 说明 |
|---|---|
| 硅基流动 | SiliconCloud 官网配置方法请参考配置文档 该并发较低,建议把线程设置为5以下。 |
| DeepSeek | DeepSeek 官网,建议使用 deepseek-v3 模型。 |
| Ollama本地 | Ollama 官网 |
| 内置公益模型 | 内置基础大语言模型(gpt-4o-mini)(公益服务不稳定,强烈建议请使用自己的模型API) |
| OpenAI兼容接口 | 如果有其他服务商的API,可直接在软件中填写。base_url 和api_key |
注:如果用的 API 服务商不支持高并发,请在软件设置中将“线程数”调低,避免请求错误。
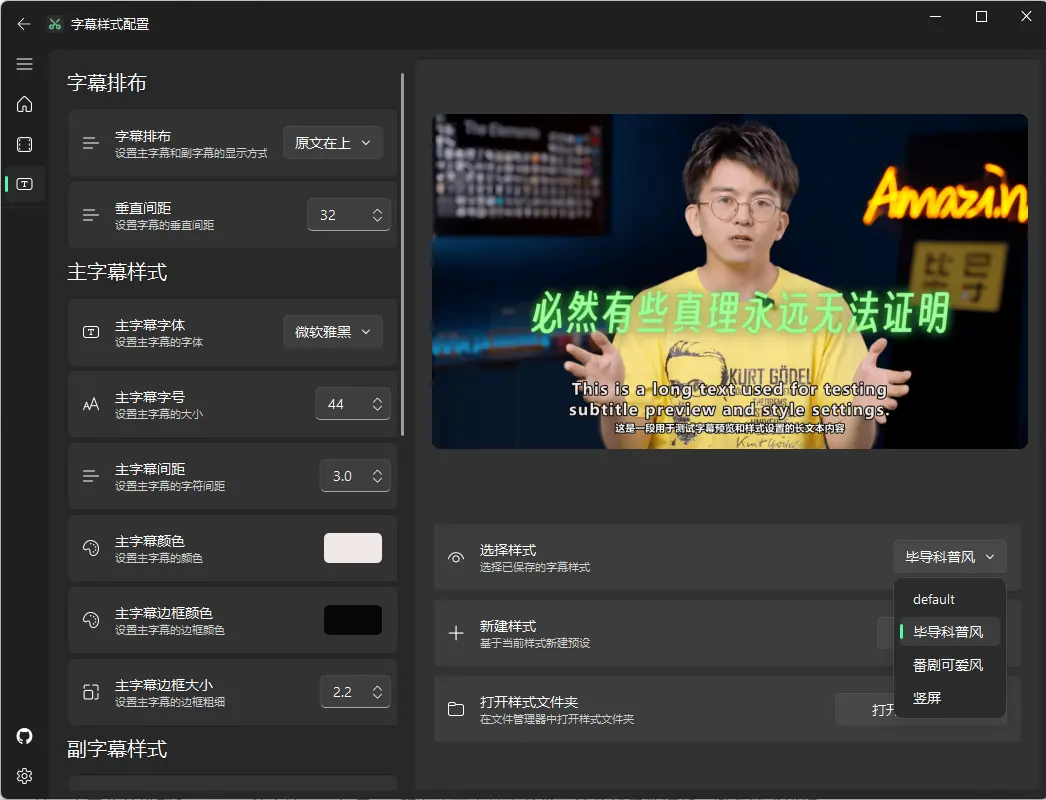
提供丰富的字幕样式模板,如科普风、新闻风、番剧风等,支持多种字幕格式(SRT、ASS、VTT、TXT),满足不同用户的需求。
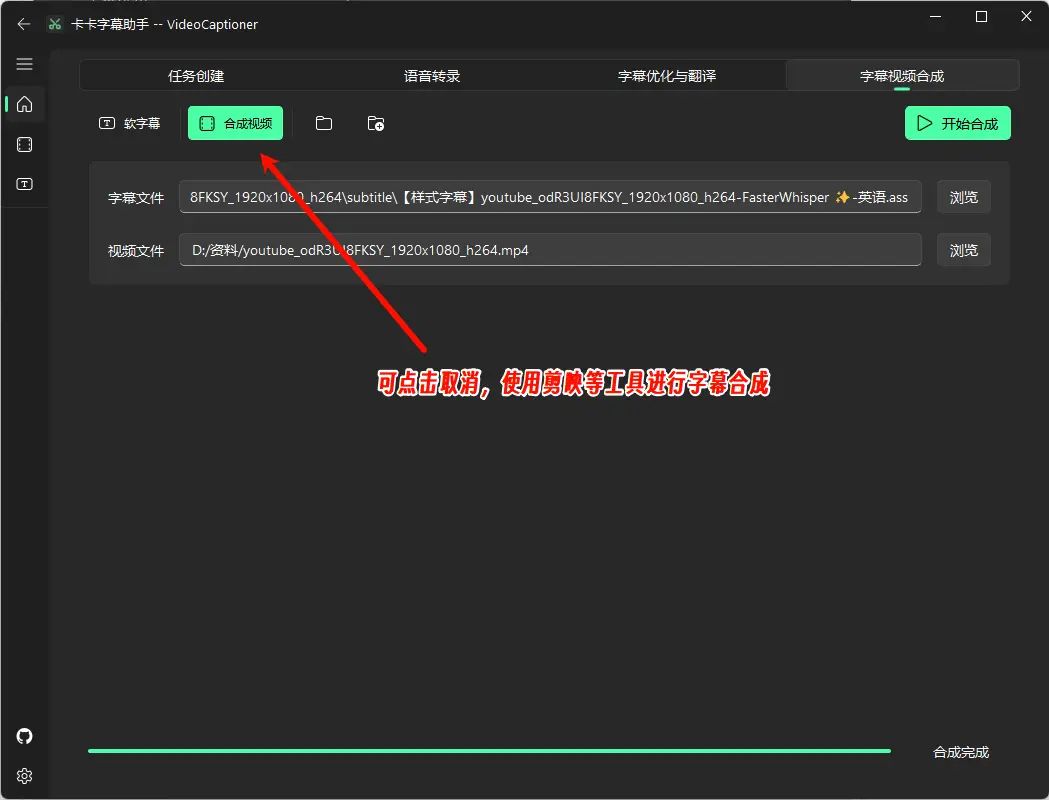
支持将字幕烧录到视频中,也支持生成软字幕,方便用户根据需求选择。注:最后一步合成视频,建议取消,将字幕导入到剪映这类剪辑软件进行合成,灵活性更高。
视频合成:开启后,会根据合成字幕视频;关闭将跳过视频合成的流程。
软字幕:开启后,字幕不会烧录到视频中,处理速度极快。但是软字幕需要一些播放器(如PotPlayer)支持才可以进行显示播放。而且软字幕的样式不是软件内调整的字幕样式,而是播放器默认的白色样式。