
Epicenter - 最新版
Epicenter 是一个正在演进的开源应用生态系统,致力于构建一个完全由用户掌控的本地智能工作环境。此前以 Whispering 之名广为人知的转录工具,现已正式升级为 Epicenter Whispering,并成为 Epicenter 生态系统中的首个成员。

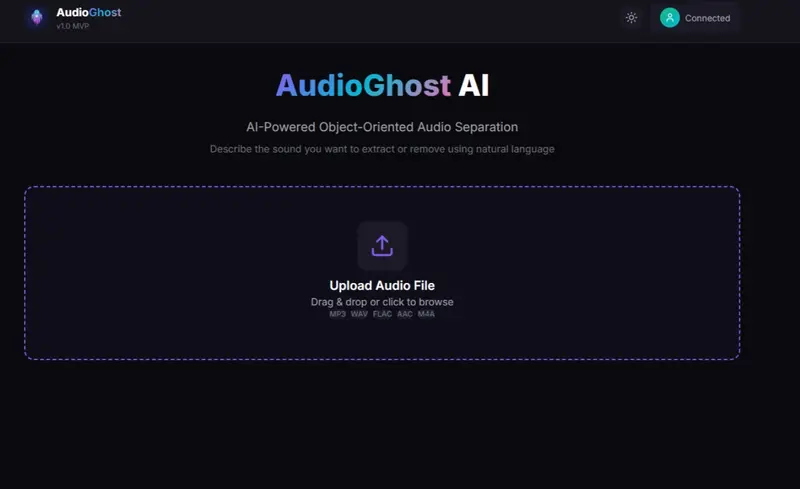
AudioGhost AI基于 Meta Facebook AI 发布的 SAM-Audio(Segment Anything Model for Audio),提供图形界面、内存优化与全流程本地部署支持。
1.7MB0 人已下载 手机查看
![AudioGhost AI:基于 SAM-Audio 的面向对象音频分离工具的使用截图[1]](https://pic.sd114.wiki/wp-content/uploads/2025/12/1766689321-1766689321-AudioGhost-AI-3.webp)
用一句话描述你想提取的声音 ——“人声”、“狗吠”、“背景鼓点”——AudioGhost 即可将其从复杂音频中精准分离。

AudioGhost AI基于 Meta Facebook AI 发布的 SAM-Audio(Segment Anything Model for Audio),提供图形界面、内存优化与全流程本地部署支持。
| 组件 | 要求 |
|---|---|
| Python | 3.11+ |
| GPU | CUDA 兼容显卡(精简模式 ≥4GB 显存,完整模式 ≥12GB) |
| CUDA | 12.6(推荐) |
| Node.js | 18+(用于前端) |
| 其他 | FFmpeg 与 Redis(安装脚本自动配置) |
💡 首次运行会自动下载模型(约 2–5GB,依模型大小而定),请确保网络畅通。
# Windows 用户运行(自动创建 Conda 环境、下载 Redis、安装依赖)
install.bat
start.bat # 启动后端 API、Celery 任务队列、前端服务
stop.bat # 停止所有服务
打开浏览器访问:http://localhost:3000
# 1. 创建 Conda 环境
conda create -n audioghost python=3.11 -y
conda activate audioghost
# 2. 安装 CUDA 12.6 版 PyTorch
pip install torch==2.9.0+cu126 torchvision==0.24.0+cu126 torchaudio==2.9.0+cu126 \
--index-url https://download.pytorch.org/whl/cu126
# 3. 安装 FFmpeg(用于 TorchCodec)
conda install -c conda-forge ffmpeg -y
# 4. 安装 SAM-Audio(需 Hugging Face 访问权限)
pip install git+https://github.com/facebookresearch/sam-audio.git
# 5–7. 安装前后端依赖(略,详见原文)
# 8. 启动服务(三终端并行)
# 终端1: uvicorn main:app --port 8000
# 终端2: celery -A workers.celery_app worker --loglevel=info --pool=solo
# 终端3: npm run dev
backend/.hf_token)| 模型 | 显存 | 推荐 GPU |
|---|---|---|
| Small | ~6 GB | RTX 3060 / 4060 |
| Base | ~7 GB | RTX 3070 / 4070 |
| Large | ~10 GB | RTX 3080 / 4080 |
💡 启用 High Quality Mode(float32) 可提升分离精度,显存增加 2–3GB。
| 模型 | 首次运行 | 后续运行 | 实时倍率 |
|---|---|---|---|
| Small | ~78s | ~25s | 10x |
| Base | ~100s | ~29s | 9x |
| Large | ~130s | ~41s | 6.5x |
首次运行包含模型下载与加载,后续使用缓存加速。
AudioGhost 通过以下方式降低显存需求(最高节省 40%):
| 裁剪组件 | 节省显存 |
|---|---|
| 视觉编码器 | ~2 GB |
| 视觉排序器 | ~2 GB |
| 文本排序器 | ~2 GB |
| 片段预测器 | ~1–2 GB |
实现策略:
predict_spans=False + reranking_candidates=1;bfloat16 混合精度(可选 float32);POST /api/separate/
表单参数:
file: 音频文件description: 文本提示(如 “人声”)mode: extract 或 removemodel_size: small / base / large(默认 base)响应:
{ "task_id": "a1b2c3", "status": "pending" }
GET /api/separate/{task_id}/status
GET /api/separate/{task_id}/download/ghost # 提取部分
GET /api/separate/{task_id}/download/clean # 移除后剩余
small 模型;bin 目录加入系统 PATH。backend/.hf_token 文件是否存在且有效。












