
Awesome Clawdbot(Moltbot) Skills
社区维护了一份名为 Awesome Clawdbot (Moltbot) Skills 的精选技能集合。该列表收录了 565 项以上 来自 ClawdHub(Moltbot 官方公共技能注册表)的技能,并按功能类别组织,便于浏览与安装。
Hindsight™ 是一个开源的代理长期记忆系统,旨在解决当前 AI 代理“健忘”且无法从经验中成长的痛点。与传统的 RAG(检索增强生成)或简单的向量数据库不同,Hindsight 采用仿生记忆架构,模拟人类大脑处理信息的方式,将记忆分为世界事实、个人经历和心智模型三层。
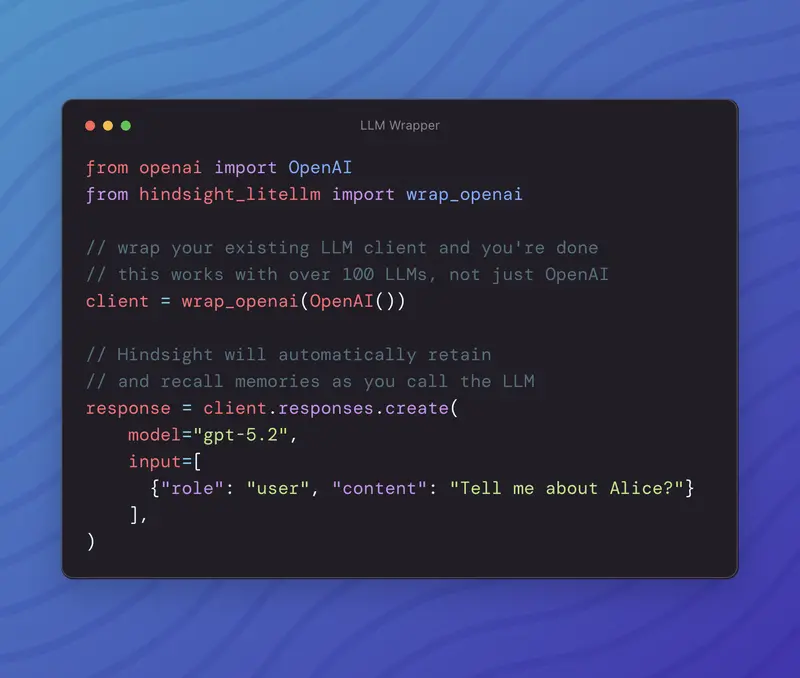
它不仅记住对话历史,更能通过反思(Reflect)从经历中提取规律,形成可复用的心智模型,从而实现越用越聪明。在权威的 LongMemEval 基准测试中,Hindsight 取得了 SOTA(State-of-the-Art) 的性能表现。
Hindsight 摒弃了单一的向量存储,转而构建一个多维度的记忆网络:
| 记忆层级 | 定义 | 示例 | 作用 |
|---|---|---|---|
| 1. 世界事实 (World Facts) | 客观存在的、不变的知识 | “炉子加热后会变烫” | 提供基础常识,避免重复学习已知真理 |
| 2. 个人经历 (Episodes) | 代理在特定时间、地点的具体交互 | “2025-06-15,我摸了炉子,手被烫伤” | 记录具体事件,包含时间、实体和因果关系 |
| 3. 心智模型 (Mental Models) | 通过反思经历得出的规律与洞察 | “接触高温物体会导致疼痛,应避免直接触摸” | 核心差异点:从经历中提炼通用规则,指导未来决策 |
在回忆(Recall)时,Hindsight 并行执行四种搜索策略,并通过倒数排名融合(RRF)和交叉编码器重排序,确保最高相关性:
Hindsight 支持 Docker 部署(推荐生产环境)和 Python 嵌入式运行(适合本地测试/轻量应用)。
export OPENAI_API_KEY=sk-xxx
docker run --rm -it --pull always -p 8888:8888 -p 9999:9999 \
-e HINDSIGHT_API_LLM_API_KEY=$OPENAI_API_KEY \
-v $HOME/.hindsight-docker:/home/hindsight/.pg0 \
ghcr.io/vectorize-io/hindsight:latest
http://localhost:8888http://localhost:9999适合快速原型开发或单机应用。
pip install hindsight-all -U
import os
from hindsight import HindsightServer, HindsightClient
# 启动临时服务器
with HindsightServer(
llm_provider="openai",
llm_model="gpt-5-mini",
llm_api_key=os.environ["OPENAI_API_KEY"]
) as server:
client = HindsightClient(base_url=server.url)
# 1. Retain: 存储记忆
client.retain(bank_id="my-bank", content="Alice works at Google")
# 2. Recall: 检索记忆
results = client.recall(bank_id="my-bank", query="Where does Alice work?")
print(results)
pip install hindsight-client -U
# 或
npm install @vectorize-io/hindsight-client
Python 示例:
from hindsight_client import Hindsight
client = Hindsight(base_url="http://localhost:8888")
# 存储带上下文的记忆
client.retain(
bank_id="user_123",
content="Alice got promoted to senior engineer",
context="career update",
timestamp="2025-06-15T10:00:00Z"
)
# 反思并生成洞察
insights = client.reflect(bank_id="user_123", query="What are Alice's career trends?")
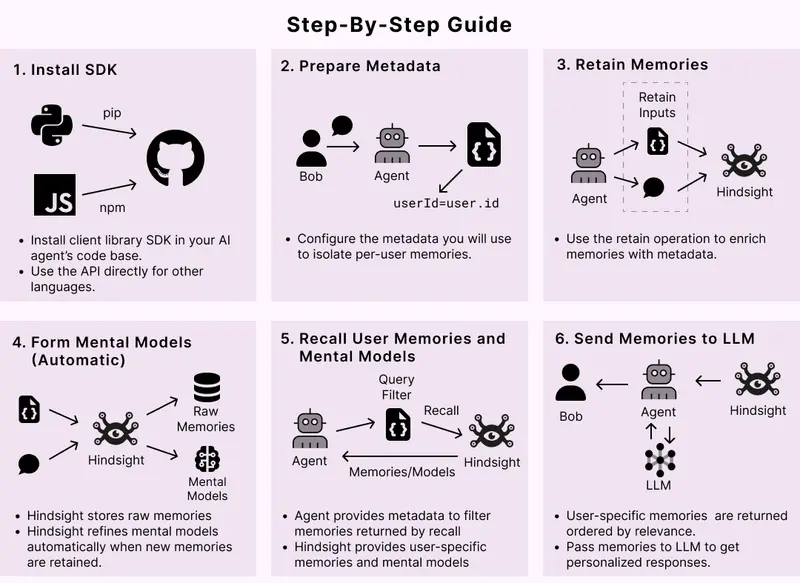
Hindsight 提供三个原子操作,完美对应人类认知过程:
将新信息摄入系统。后台自动提取实体、关系、时间,并规范化存储。
client.retain(bank_id="bank_id", content="Content to remember")
根据查询检索最相关的记忆片段。支持时间范围和元数据过滤。
client.recall(bank_id="bank_id", query="Query string")
对现有记忆进行深度分析,生成新的心智模型或洞察。这是实现“学习”的关键。
client.reflect(bank_id="bank_id", query="What patterns do you see in recent failures?")
Hindsight 提供了专门的 Skill,让 Claude Code、Cursor 等编码助手能即时访问文档和历史上下文。
npx skills add https://github.com/vectorize-io/hindsight --skill hindsight-docs













