Stream
Stream 是一款戴在食指上的金属戒指,内置麦克风、触控感应器和振动马达。它不显示信息,不播放音乐,也不主动说话——它只做一件事:当你想记录一个念头时,它让你不拿出手机,也不对着空气喊话。
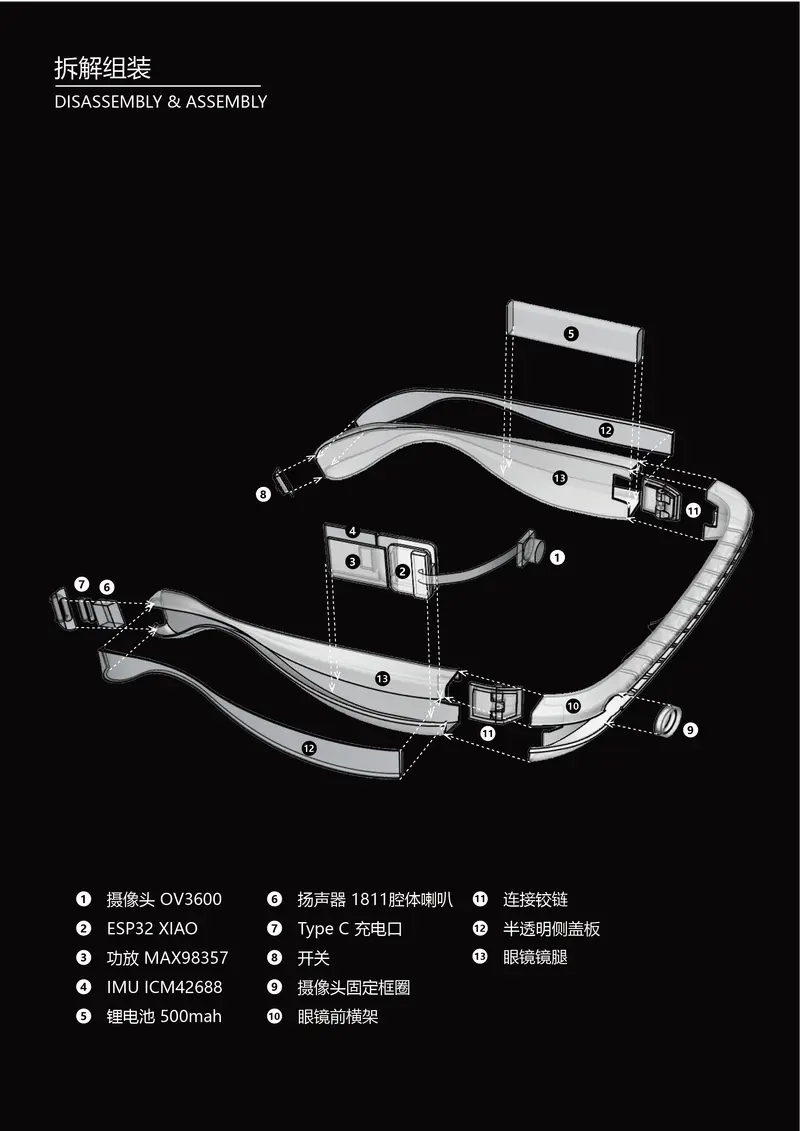
AI 智能盲人眼镜系统是一个面向视障用户的智能辅助工具原型,整合了盲道导航、过马路辅助、物品识别和语音交互等核心功能。通过视频、音频、IMU(惯性测量单元)等多模态输入,系统可提供实时语音引导与环境感知能力,帮助用户更安全地感知周围环境。
AI 智能盲人眼镜系统是一个面向视障用户的智能辅助工具原型,整合了盲道导航、过马路辅助、物品识别和语音交互等核心功能。通过视频、音频、IMU(惯性测量单元)等多模态输入,系统可提供实时语音引导与环境感知能力,帮助用户更安全地感知周围环境。
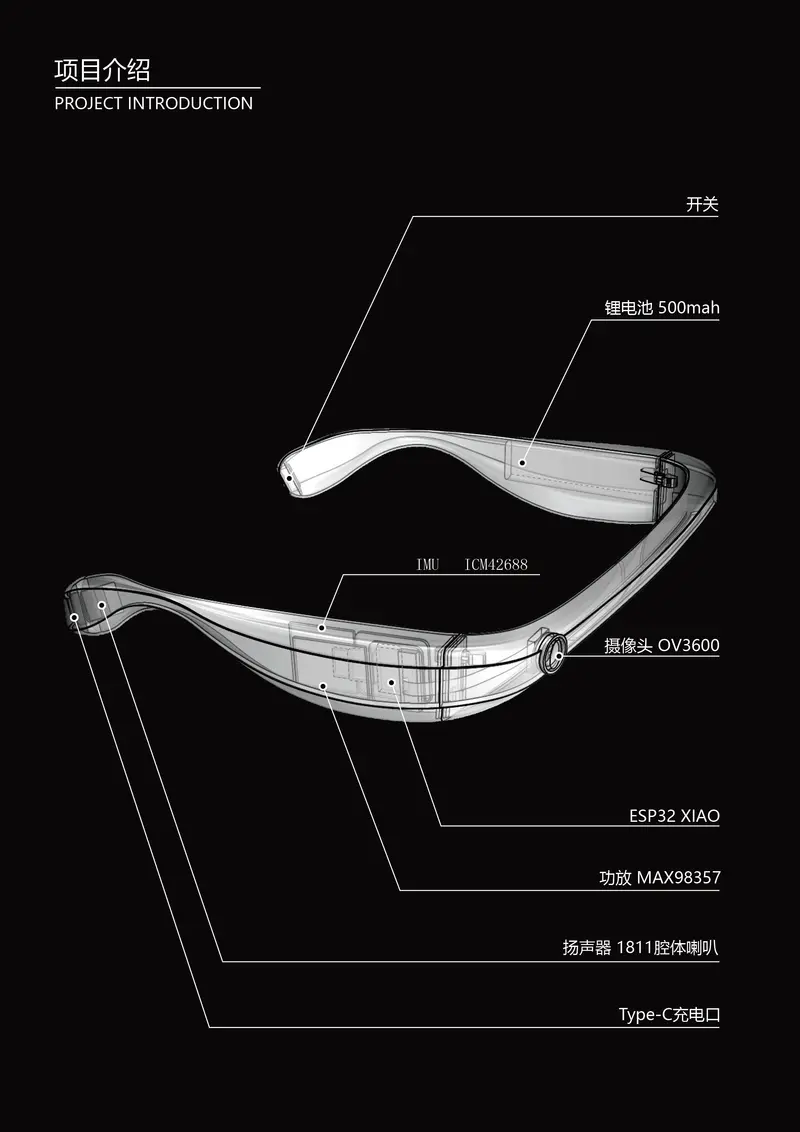
说明:本项目为技术交流与学习用途,尚未经过临床或无障碍产品认证,请勿直接用于视障人群的实际出行。