
FLORA
FLORA 是一款创意图像和视频创作工具,接入了顶级 AI 绘画和视频模型。它通过优雅的交互设计,帮助创意团队构建结构化、可扩展的工作流,提升创作速度和控制力,支持多人实时协作。
ViMax 是一个多智能体视频生成框架,支持自动化多镜头视频生成,并确保角色与场景的一致性。系统能将你的创意无缝转化为对应视频,让你专注于讲故事,而非技术实现。
主流AI视频工具仍面临几个关键限制:
这些缺陷使得AI视频难以用于真正的创作场景——比如改编小说、制作短剧,或让普通人讲述自己的故事。
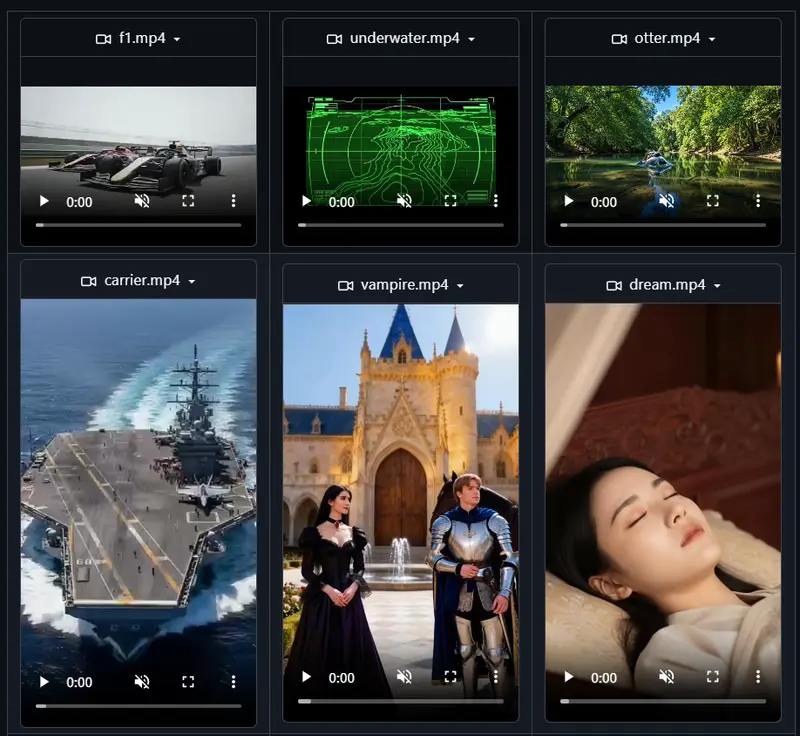
ViMax 的目标很明确:把创意直接变成可观看的视频,无需人工干预中间环节。它整合了四个传统角色的功能:
用户只需提供一个想法——一段文字、一篇小说、一张照片,甚至一句“我想演科幻片”——ViMax 就能自动完成后续所有步骤。
通过多智能体协作,将模糊的创意转化为有起承转合的故事,自动完成角色设定、情节编排和视觉呈现。
内置文学理解引擎,能读取整本小说,提取关键情节,压缩为多集剧本,并逐场景生成连贯视频,保持角色外观与叙事逻辑一致。
支持任意格式剧本输入,无论是三幕剧、广告脚本还是互动剧情,系统会自动规划镜头、构图与节奏,输出电影级画面。
上传个人照片,ViMax 可将你作为角色嵌入任何故事中,自动匹配表情、动作与场景互动,实现“你在电影里”的体验。
| 问题 | ViMax 的应对方案 |
|---|---|
| 参考图难找 | 智能检索并复用历史帧中的角色/环境特征 |
| 画面不一致 | 并行生成多候选帧,用视觉语言模型(VLM)选出最连贯的一帧 |
| 剧本质量低 | 基于RAG的长文本理解引擎,确保情节密度与角色动机合理 |
| 分镜专业门槛高 | 自动应用电影语言规则(如过肩镜头、特写节奏)生成分镜 |
| 长视频难扩展 | 通过时序追踪与资产索引,支持分钟级甚至更长视频的跨场景一致性 |
ViMax 是一个多智能体流水线系统,分为三层:
关键创新包括:
最终输出包括:高清帧序列、合成视频、制作日志及可复用的资产目录。
ViMax 不是又一个“生成5秒跳舞视频”的玩具,而是一个面向创作者的自动化影视工厂——让一个人也能完成过去需要团队协作的视频生产流程。













