
NBLM2PPTX
NBLM2PPTX 是一个专为 NotebookLM 用户设计的轻量级工具,能将 NotebookLM 导出的 PDF 演示文稿自动转换为 背景图与文字分离的 PPTX 文件。转换后的每一页都包含干净的底图和独立的可编辑文字层,便于后续修改、排版或本地化调整。
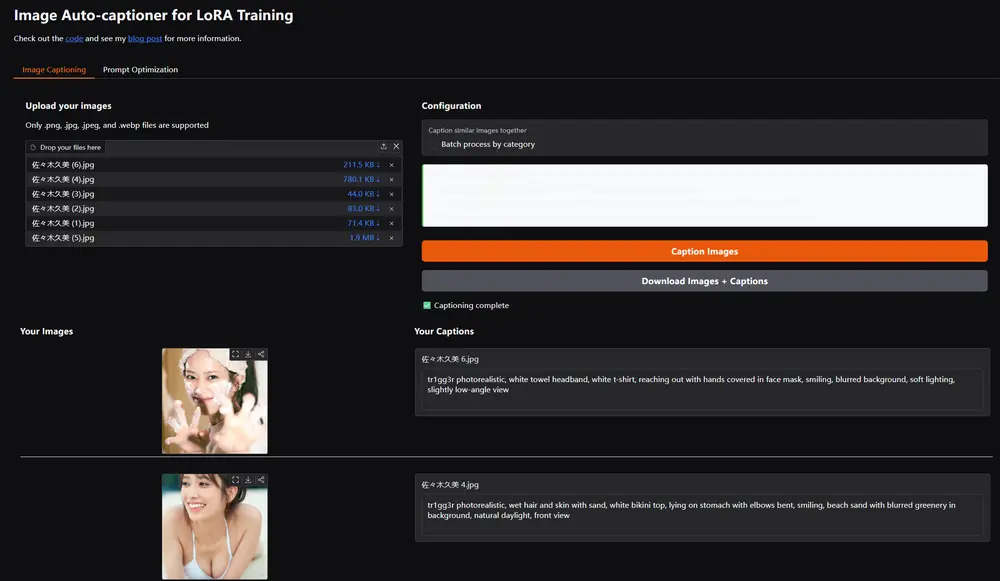
LoRACaptioner 是一款强大的开源工具,专注于解决 LoRA 训练中的标注问题。通过自动生成结构化标注和优化提示,它不仅提升了训练效果,还显著增强了生成图像的质量和一致性。
LoRACaptioner 是一款专为FLux LoRA模型训练设计的开源工具,旨在自动生成详细且结构化的图像标注,并优化推理过程中的提示,从而显著提升生成图像的质量和一致性。无论您是训练角色 LoRA 还是其他类型的 LoRA 模型,LoRACaptioner 都能帮助您解决标注不一致、训练噪声过多等问题。
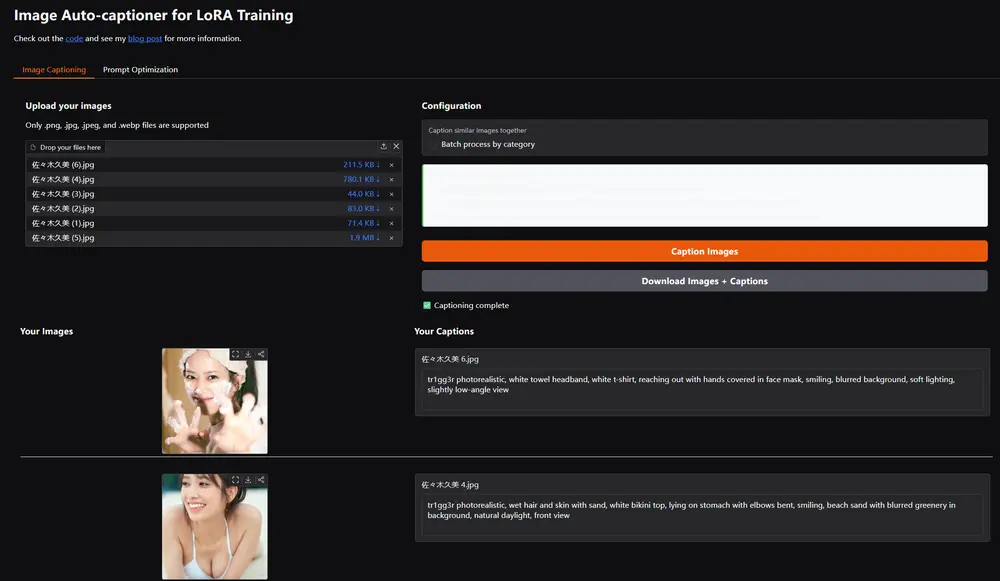
.png、.jpg、.jpeg 和 .webp)。.txt 文件保存,便于管理和使用。在图像生成社区中,许多用户在训练 LoRA 时会遇到生成图像与数据集不符的问题。经过深入研究,我们发现问题的核心在于 标注质量。低质量或不一致的标注会导致训练过程引入噪声,最终影响生成效果。
LoRACaptioner 通过以下方式解决了这一问题:
[触发词] [风格], [显著视觉特征], [服装], [姿势], [表情/情绪], [背景/场景], [光照], [相机角度]
tr1gg3r 在意大利小镇的鹅卵石街道上骑自行车
可优化为:
tr1gg3r 写实, 卷曲及肩长发, 花卉衬衫配浅蓝色紧身牛仔裤, 骑自行车, 微笑表情, 意大利小镇鹅卵石街道, 柔和午后光照, 三分之二视角
.png、.jpg、.jpeg 和 .webp 文件。如果图像格式不兼容,请转换为支持的格式。尽管 LoRACaptioner 已经能够显著提升 LoRA 训练效果,但仍有改进空间:













