首页
快讯
早报
模型
ComfyUI
新技术
百科
教程
硬件
科普
百科工具
工具
排行榜
网址提交
首页
快讯
早报
模型
ComfyUI
新技术
百科
教程
硬件
科普
百科工具
工具
排行榜
网址提交
公告
所有公告
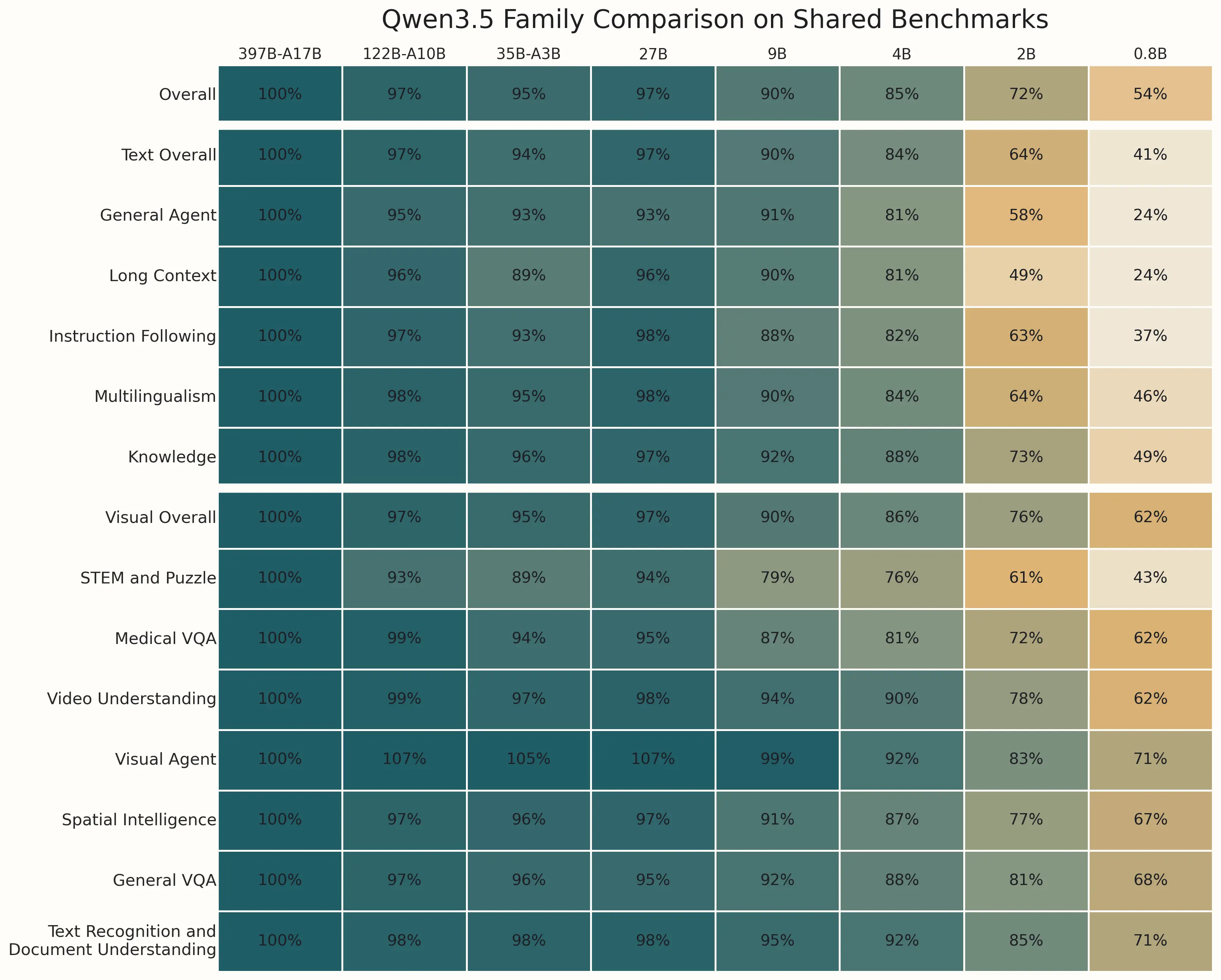
Qwen3.5系列模型在基准测试中的对比
4周前
小马良
19
0
0
主要结论:122B、35B模型,尤其是27B模型在很多方面仍保持着旗舰模型的性能水平,而2B和0.8B模型在长上下文理解和智能体任务上的表现则明显下滑较多。
来源:https://www.reddit.com/r/LocalLLaMA/comments/1ro7xve/qwen35_family_comparison_on_shared_benchmarks
上一篇
GPT-5.4现已在GitHub Copilot中向专业和商业用户提供
下一篇
X 称你可以阻止 Grok 编辑你的照片
暂无评论
暂无评论...
热门文章
日榜
周榜
月榜
Kimi 会员计费大升级:告别“按次计数”,迎来“统一额度”时代
7天前
337
LMArena 最新排名出炉!阿里千问杀入全球前五,Qwen3.5-Max-Preview 力压豆包、Kimi 成国产最强
3周前
161
美团开源 5677 亿参数 LongCat-Flash-Prover:专攻数学证明,MiniF2F 通过率高达 97.1%
2周前
144
Cursor 3 正式发布:软件开发进入“智能体群”时代,打造统一自主工作区
4天前
36
谷歌推出升级Gemini 2.0模型,助力AI 搜索与助手全面进化
1年前
289
Genspark 超级智能体全新升级:您的 AI 秘书来了,用一句话掌控邮箱、日历与文件
10个月前
204
查看完整榜单
网址
网址
文章
软件
模型
网址
日榜
周榜
月榜
S.H.I.T
在主流学术界为顶刊版面、高影响因子和“非升即走”的考核指标疯狂内卷之时,一场名为“学术垃圾”的反叛运动正在角落里悄然兴起。一群“想开了”的硕博研究生和青年学者(青椒),不再试图迎合传统的学术评价体系,而是隆重推出了一系列名字惊世骇俗的“旗舰”期刊——《SHIT》、《Notrue》、《Silence》、《Crazy》。
新
Flova
Flova AI 最近宣布集成字节跳动最新的视频生成模型——Seedance 2.0。这不仅仅是一个新模型的上线,更意味着普通创作者现在也能轻松制作出长达 60 至 90 秒、角色稳定、剧情连贯的电影级短剧。
ITELLOU
ITELLYOU(也称为NEXT, ITELLYOU)是一个专注于提供微软原版软件资源的非官方网站,主要帮助用户获取未经修改的微软产品镜像,如Windows操作系统、Office办公软件和开发工具等。
Tripo
Tripo AI 是一家领先的 AI 驱动 3D 建模解决方案提供商,允许用户使用文本、单张图像、多张图像、涂鸦或视频等输入,快速创建高质量的 3D 模型和环境。
即梦 CLI
即梦 CLI (Jimeng CLI) 是字节跳动官方推出的面向 AI Agent 的命令行工具包。它打破了图形界面的限制,让任何 AI 智能体(如基于 OpenClaw 的助手)都能直接调用即梦强大的 Seedance 2.0 旗舰模型,实现图片与视频的自动化生成。
CoPaw
阿里云旗下阿里桌面 Agent 工具 CoPaw 正式开源,CoPaw 原生支持钉钉、飞书、QQ、Discord、iMessage 等聊天软件和平台,内置了多种 Skills,用户可一键本地部署也可通过阿里云计算巢和魔搭社区创空间实现一键云端部署,并调用千问系列等主流模型,是业界部署门槛最低的 Agent 工具之一。
查看完整榜单