
新美国撤销争议AI硬件出口规则:取消“对等投资”要求,新规仍在制定
美国商务部已正式撤销一项争议性AI硬件出口规则草案,该草案曾要求海外大型AI集群运营商必须投资美国AI基础设施才能采购英伟达、AMD等厂商的高端AI加速器。目前,针对AI硬件的新出口框架仍在制定中。 ...
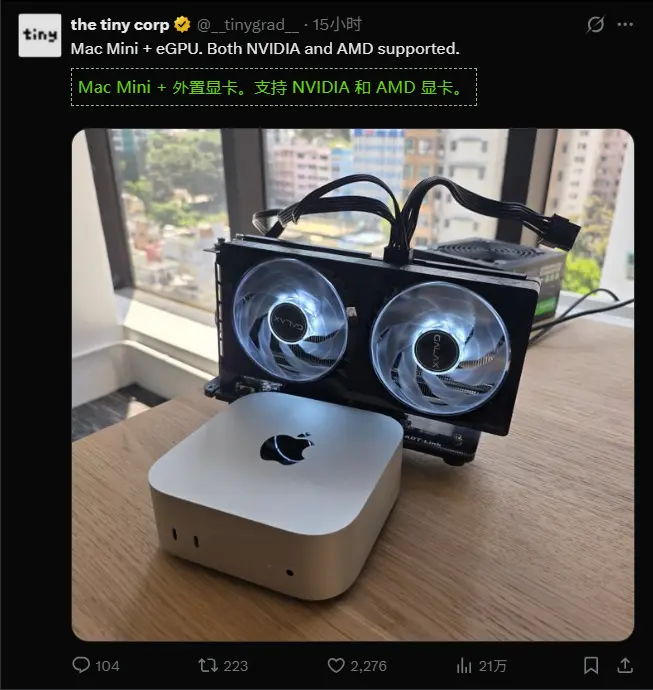
新Mac Mini 变身 AI 工作站!TinyCorp 实现外接 NVIDIA/AMD 显卡跑本地大模型
在 OpenClaw 热潮推动下,苹果 Mac Mini 成为热门本地 AI 计算设备,而 AI 初创公司 TinyCorp 进一步突破性能上限,成功通过外接显卡方案,将 Mac Mini 打造成更强...

新高管称AI大幅提升生产力,报告实测净增益仅每周16分钟
AI被企业高管视为提升效率的核心工具,但Foxit发布的《文档智能状况报告》显示,在扣除审核与校验时间后,AI带来的实际生产力提升远低于预期。 感知与现实巨大差距:净收益仅16分钟 89%的高管认为A...
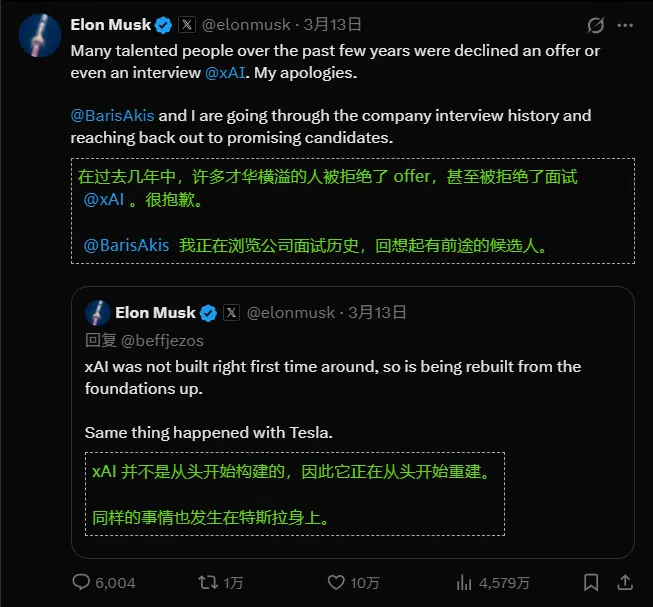
新xAI 遭遇“创始团队大清洗”:11 人仅剩 2 人,马斯克空降“整顿者”重塑编程能力
埃隆·马斯克(Elon Musk)旗下的 xAI 正经历一场前所未有的内部动荡。据《金融时报》及多方信源报道,因对 Grok 编程产品 的表现极度不满,马斯克启动了严厉的重组计划,导致多位联合创始人被...

新Chrome 146 原生支持 WebMCP:Agent 操作网页的“去后端化”革命,却陷“鸡生蛋”困局
谷歌在 Chrome 146 版本中迈出了关键一步:原生支持 WebMCP (Web Model Context Protocol)。这一更新标志着 AI Agent 与浏览器交互的方式发生了范式转移...

新AMD 官方完整教程:Windows 本地部署 OpenClaw AI 智能体(双硬件方案)
AMD 正式发布了面向 Windows 系统的技术指南,详细介绍了如何在 AMD 硬件平台上通过两条不同路径实现 OpenClaw 的本地化部署,这两条方案分别被命名为 RyzenClaw 和 Rad...
新Digg 重启梦碎:公测仅两月便因“AI 机器人洪流”被迫关停
曾经在互联网早期与 Reddit 分庭抗礼的新闻聚合网站 Digg,在其备受瞩目的“重生”计划中再次遭遇重创。在公开测试版上线仅仅 两个月 后,Digg 官方宣布将立即停止运营,进行“硬重置”(Har...

新微软确认:Copilot AI 助手今年将登陆 Xbox Series X|S,化身你的“游戏军师”
微软正在加速将 AI 深度融入游戏生态。继在 Windows 11、Xbox 移动应用以及新款掌机 Xbox Ally 上部署 Copilot 之后,微软正式宣布:游戏专用版 Copilot 将于 2...
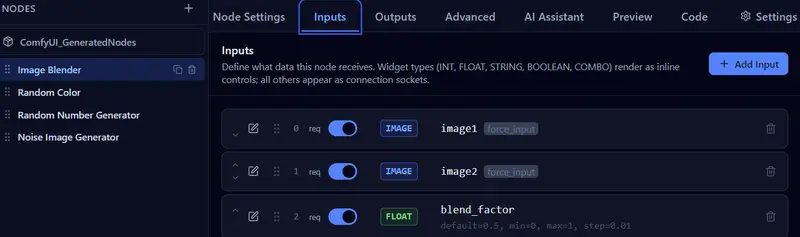
新Comfy Node Designer:零代码打造 ComfyUI 自定义节点,AI 辅助逻辑生成
Comfy Node Designer 是一款专为 ComfyUI 开发者设计的桌面图形界面工具。它彻底颠覆了传统开发流程,让你无需编写任何样板代码,即可通过直观的拖拽和配置,快速创建、编辑和导出功能...

新砺算科技 TrueGPU 天图架构显卡正式发售:自研 LX 7G106 对标 RTX 4060,全栈自主破局
在 AWE2026 大展上,国产 GPU 厂商砺算科技迎来了历史性时刻:其基于完全自研 TrueGPU 天图架构 的 Lisuan eXtreme (LX) 系列显卡正式开启公开发售。这不仅标志着砺算...





