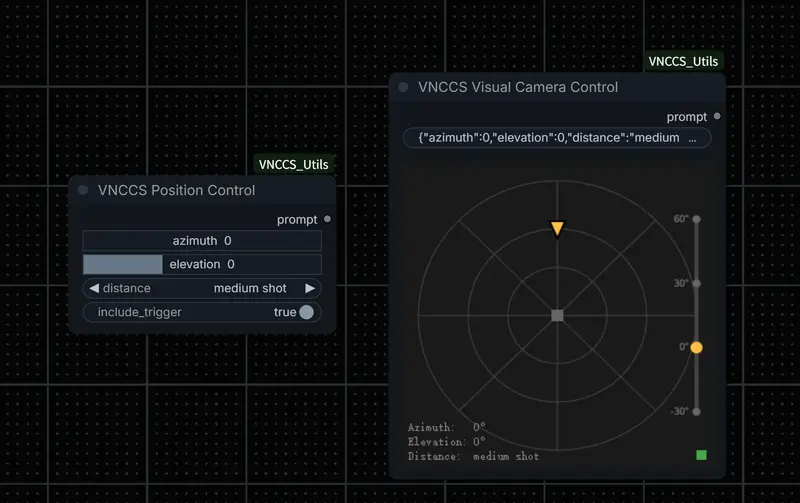
ComfyUI VNCCS 工具集:新增交互式相机控制节点,简化多角度 LoRA 提示词生成
在使用多角度 LoRA(如 Qwen-Image-Edit-2511-Multiple-Angles)进行图像生成时,如何准确描述相机视角常是一大难题。传统方式需手动输入如 “front view, ...
ComfyUI-QuantOps:支持 INT8 块量化模型加载,降低显存占用提升推理效率
在本地运行Qwen Image 、WAN2.2等大模型时,显存占用高、推理速度慢是常见瓶颈。模型量化(如 INT8、FP8)可显著降低内存需求并提升推理吞吐,但 ComfyUI 原生对非标准量化格式支...

UniVideo:滑铁卢大学与快手推出统一视频生成与编辑模型,支持理解、生成、编辑一体化
长久以来,视频 AI 能力被割裂为多个独立任务: 理解:靠视觉语言模型(如 Qwen-VL) 生成:依赖扩散模型(如 Sora、HunyuanVideo) 编辑:需专门的编辑网络或掩码引导 这种碎片化...
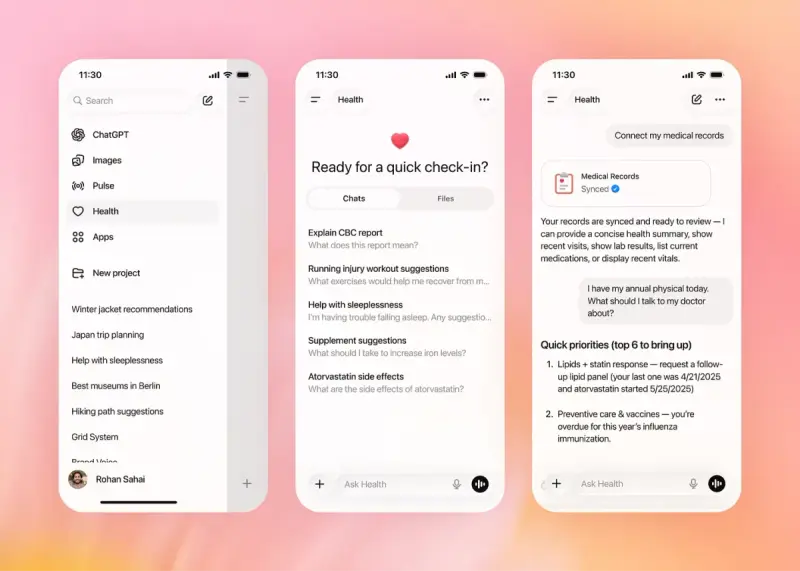
OpenAI 推出 ChatGPT Health:支持连接健康数据,提供个性化医疗建议
OpenAI 正式在 ChatGPT 中推出 ChatGPT Health —— 一个专为健康与保健场景设计的独立功能模块。目前,该功能已在网页端和 iOS 平台开启小范围测试,并计划在未来几周向全球...
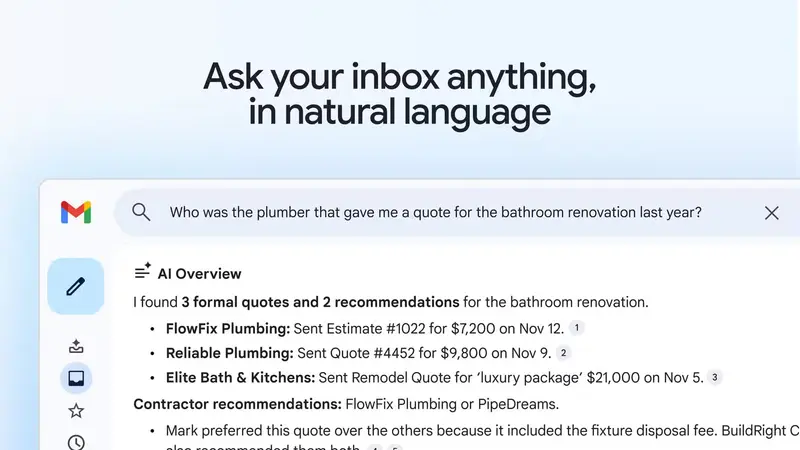
Gmail 新增 AI 收件箱、邮件摘要与校对功能,Gemini 深度整合
谷歌正将 Gemini AI 更深地嵌入其核心产品。继 Gmail 陆续上线部分 AI 辅助功能后,2026 年初迎来一次重大升级:AI 概览、校对、建议回复全面开放,并首次推出 “AI 收件箱” 全...
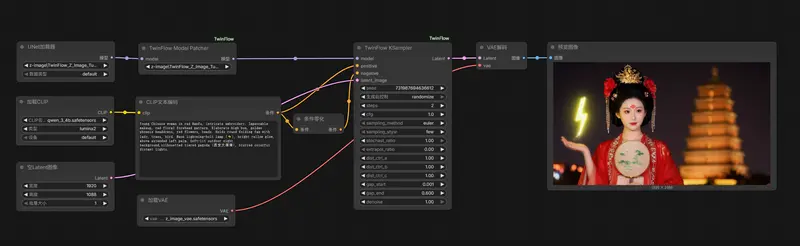
ComfyUI-TwinFlow:加速Qwen-Image、Z-Image生成速度,兼容 LoRA 与 ControlNet
TwinFlow是一种通过自对抗流(Self-adversarial Flows)将大型扩散模型(如 Qwen-Image、Z-Image)加速至 1 步或极低步数(2–4 步)生成的先进技术。 1步...
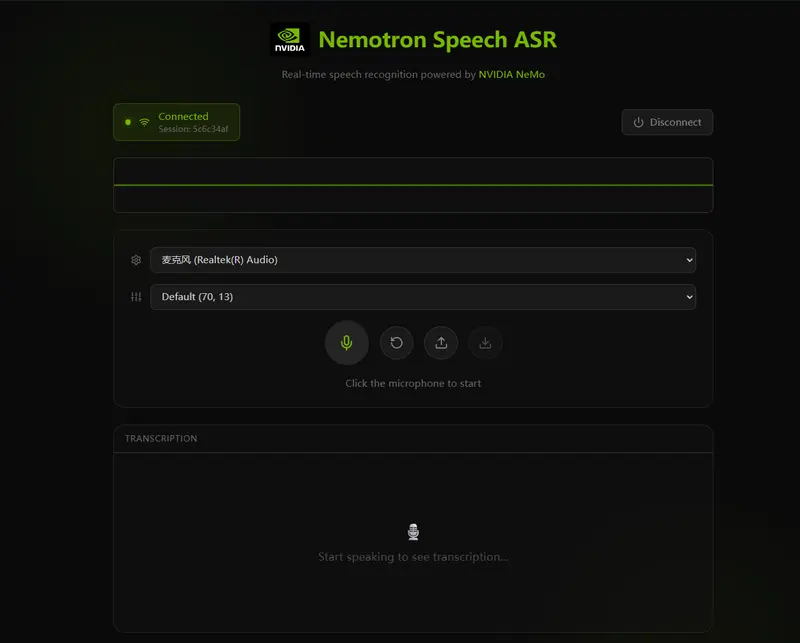
Nemotron-Speech-Streaming-En-0.6B:面向低延迟与高吞吐的流式语音识别模型
英伟达推出的 Nemotron-Speech-Streaming-En-0.6B 是 Nemotron Speech 系列中的首个统一语音识别(ASR)模型,专为实时英语转录场景设计。它同时支持低延迟...
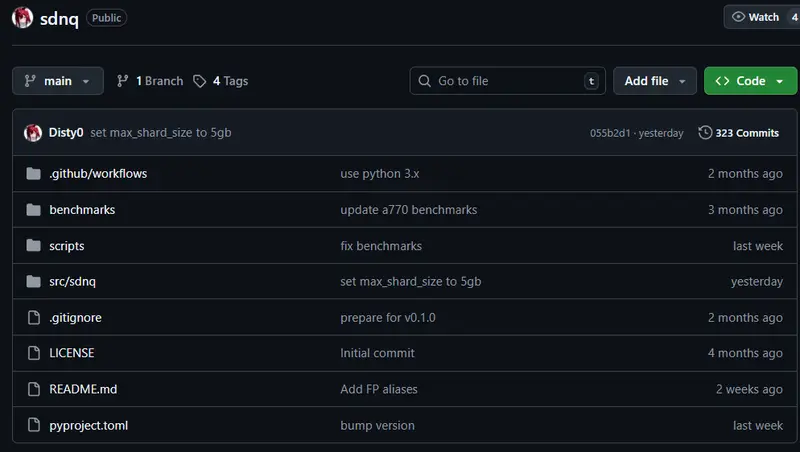
SDNQ 量化:跨平台模型压缩方案,显著降低显存占用并提升推理速度
SDNQ(Stable Diffusion Next Quantization) 是 SD.Next 中集成的一套全平台量化系统,支持 19 种整数量化 与 69 种浮点量化 方案,可在 英伟达、AM...
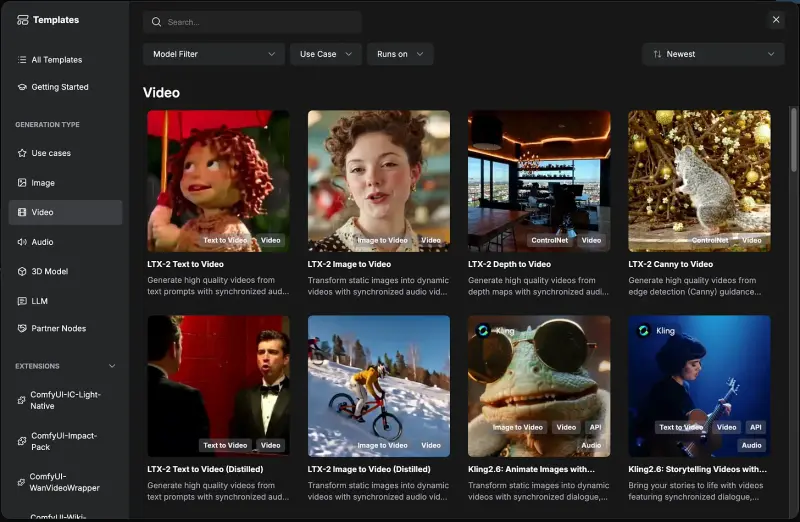
LTX-2 首日集成 ComfyUI,支持同步音视频生成与多模态控制
开源音视频生成模型 LTX-2 已于发布当日集成至 ComfyUI 核心,成为首个在 ComfyUI 中获得原生支持的同步音视频基础模型。用户无需安装额外插件,即可直接调用其音画协同生成能力。 LTX...

英伟达RTX 加速本地 AI:LTX-2+ComfyUI升级,性能飙升3倍、显存占用大降
2025年堪称PC端AI爆发元年——小型语言模型(SLM)准确率翻倍,开发者工具生态成熟度激增,用户下载量较2024年暴涨十倍。而在本届CES展会上,英伟达的一波重磅RTX加速技术升级,更是直接解锁了...





