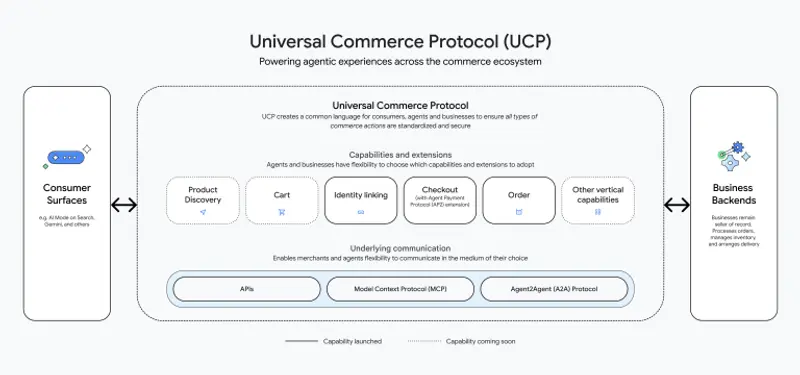
谷歌发布通用商务协议(UCP):让 AI 智能体真正“促成交易”
在 2026 年全美零售联合会(NRF)大会上,谷歌联合 Shopify、Etsy、Wayfair、Target 和沃尔玛等零售巨头,正式推出 通用商务协议(Universal Commerce Pr...
继 Health 后,OpenAI 将推出 Jobs 智能体,切入职业服务赛道
继推出 ChatGPT Health 后,OpenAI 正在内部测试一款名为 ChatGPT Jobs 的新智能体,旨在为用户提供简历优化、职位匹配、职业规划等一站式求职支持。 目前该功能仍处于“内部...
xAI 即将推出 Grok Build:本地优先的 Vibe Coding 智能体
继 Grok 4.2 发布在即的消息后,xAI 正在为开发者准备一项新工具:Grok Build——一个专注于 Vibe Coding(氛围编程) 的智能体系统,旨在将 Grok 深度融入本地开发工作...
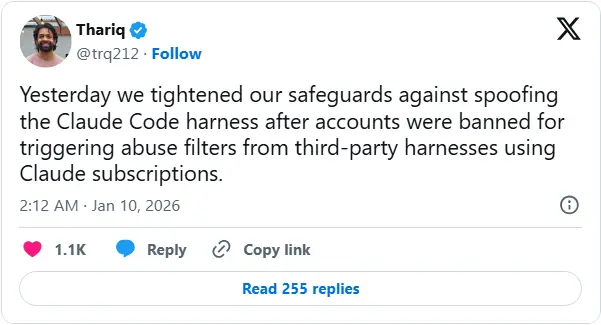
Anthropic 双线封杀:第三方工具遭技术拦截,xAI 等竞品被切断 Claude 使用权
Anthropic 近期启动双重管控行动:一方面通过技术防护封杀伪装官方客户端的第三方工具,另一方面以商业条款为由,切断 xAI 等竞争对手对 Claude 模型的未授权访问。这一系列操作不仅冲击了 ...
腾讯优图实验室推出 Youtu-LLM:持 128K 上下文、本地运行,专为端侧 AI 设计
在大模型普遍走向百亿、千亿参数的今天,腾讯优图实验室推出了一款仅 1.96B 参数的轻量级语言模型——Youtu-LLM。它不追求规模堆砌,而是以 STEM 能力与原生智能体(Agentic)能力为核...
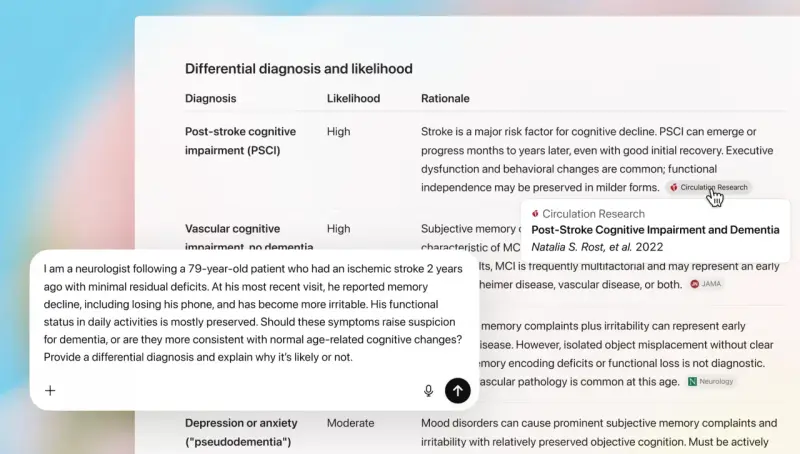
OpenAI 推出符合 HIPAA 规范的 "医疗版 ChatGPT",搭载 GPT-5 模型
昨日,OpenAI 宣布推出 ChatGPT for Health,这是一个专注于健康与保健的专用体验。ChatGPT Health 能够连接主流的医疗记录与健康应用程序,以提供更个性化、更优质的回答...
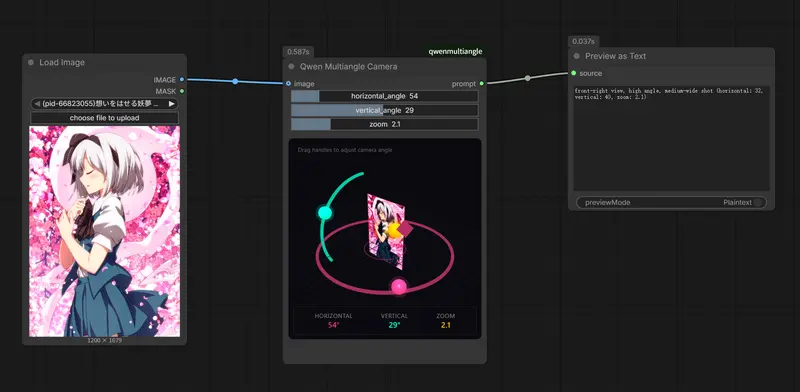
ComfyUI-qwenmultiangle:交互式 3D 相机控制,一键生成多角度提示词
ComfyUI-qwenmultiangle 是一个专为多角度图像生成设计的 ComfyUI 自定义节点。它通过嵌入 Three.js 3D 视口,让你像操作 3D 软件一样,直观地调整虚拟相机的方位...
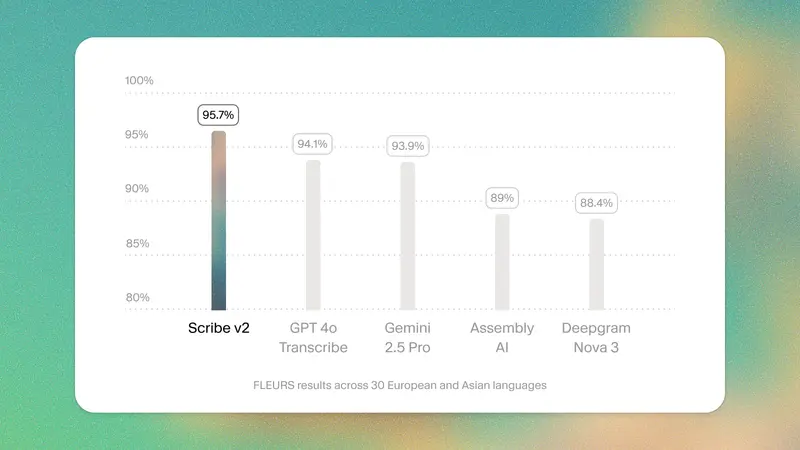
ElevenLabs 推出 Scribe v2:支持 90+ 语言的高精度批量转录模型
ElevenLabs 正式发布 Scribe v2——一款专为大规模音视频内容处理设计的新一代语音转文字模型。与主打低延迟的 Scribe v2 Realtime 不同,Scribe v2 面向批量转...

阿里开源 Qwen3-VL 多模态检索模型:Embedding + Reranker 两阶段提升跨模态精度
在多模态 AI 应用日益普及的今天,如何高效检索混合了文本、图像、截图甚至视频的内容,仍是技术难点。传统方案往往依赖多个专用模型,导致系统复杂、语义割裂。 官方说明:https://qwen.ai/b...
Claude Code 2.1.0重磅更新:代理工作流全面升级,开发者体验再优化
Anthropic 正式推出 Claude Code v2.1.0,这款以“氛围编码”为核心的开发环境迎来重要迭代。此次更新围绕代理生命周期控制、技能开发、会话可移植性和多语言输出四大核心方向展开,累...





