![ComfyUI已支持 FLUX.2 [klein]:4B 模型实现 1.2 秒本地图像生成与编辑](https://pic.sd114.wiki/wp-content/uploads/2026/01/1768500082-1768500082-FLUX.2-klein-4.webp~tplv-o4t1hxlaqv-image.image)
ComfyUI已支持 FLUX.2 [klein]:4B 模型实现 1.2 秒本地图像生成与编辑
ComfyUI 已在第一时间支持黑森林实验室(Black Forest Labs)最新发布的 FLUX.2 [klein] 模型系列。该系列将文生图、图生图与多参考图像编辑统一于单一紧凑架构中,在消费...
![黑森林实验室发布 FLUX.2 [klein]:统一生成与编辑的最快开源模型](https://pic.sd114.wiki/wp-content/uploads/2026/01/1768500030-1768500030-FLUX.2-klein-2.webp~tplv-o4t1hxlaqv-image.image)
黑森林实验室发布 FLUX.2 [klein]:统一生成与编辑的最快开源模型
黑森林实验室(Black Forest Labs)今日正式推出 FLUX.2 [klein] 模型系列——这是目前速度最快、体积最小的高质量图像生成模型家族。它将文生图、图像编辑与多参考图生成统一于单...
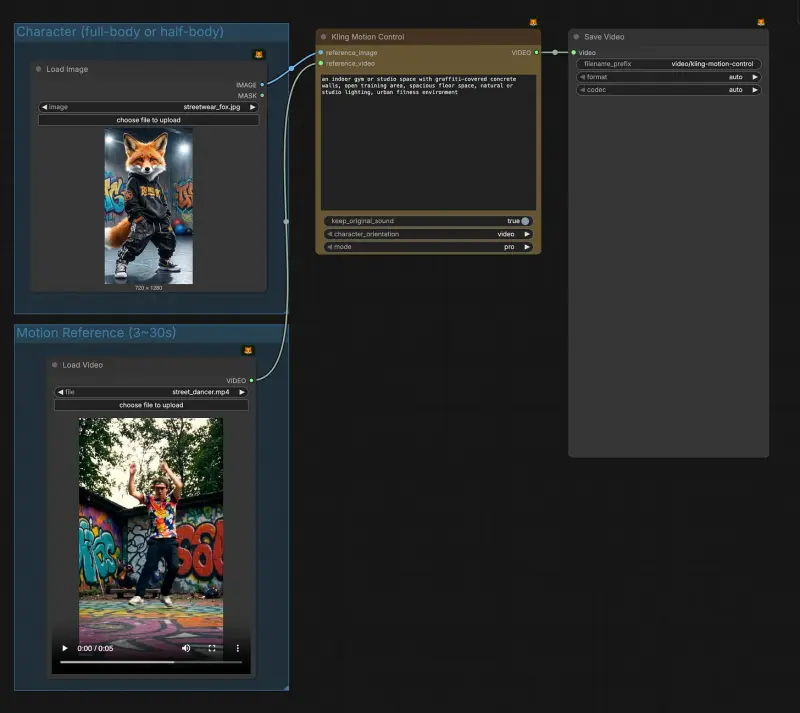
可灵2.6 运动控制登陆 ComfyUI:用视频精准驱动角色动作与表情
ComfyUI 官方近日正式上线 Kling 2.6 运动控制(Motion Control) 功能。该能力允许用户通过一段参考视频,将其中的人物动作与表情精确迁移到自定义角色图像上,实现高度一致且自...
智谱AI开源GLM-TTS:LLM驱动的高质量TTS系统,支持零样本克隆与情感增强
智谱AI推出的GLM-TTS是一款基于大语言模型的文本到语音合成系统,创新性采用LLM+Flow模型的两阶段架构,不仅实现了零样本语音克隆、流式推理等实用功能,还通过多奖励强化学习框架,大幅提升了语音...
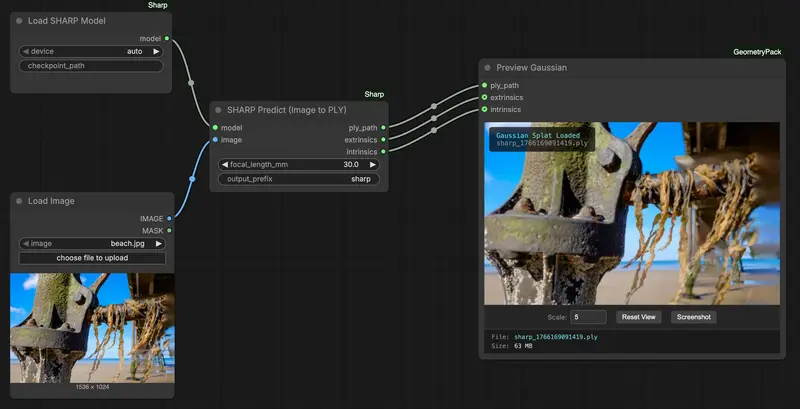
ComfyUI-Sharp:单图 3D 高斯溅射重建,基于苹果SHARP 模型的 ComfyUI 封装节点
ComfyUI-Sharp 是对 Apple 研究项目 SHARP(Single-view High-quality 3D Reconstruction with Priors)的 ComfyUI 集...

智谱AI开源GLM-Image:自回归+扩散混合架构,攻克知识密集型图像生成难题
智谱AI正式推出GLM-Image——业界首个开源的工业级离散自回归图像生成模型。这款模型创新性地采用自回归模块+扩散解码器的混合架构,既继承了自回归模型对复杂语义的精准理解能力,又兼具扩散模型高保真...

谷歌Veo 3.1重磅更新:参考图生成竖屏视频,支持4K超分赋能创作者
在AI视频生成领域持续发力的谷歌,于2026年推出了Veo 3.1版本更新,不仅强化了“从素材到视频”的核心功能,还新增竖屏视频输出、升级4K超分辨率技术,并且将工具无缝接入YouTube创作者生态...
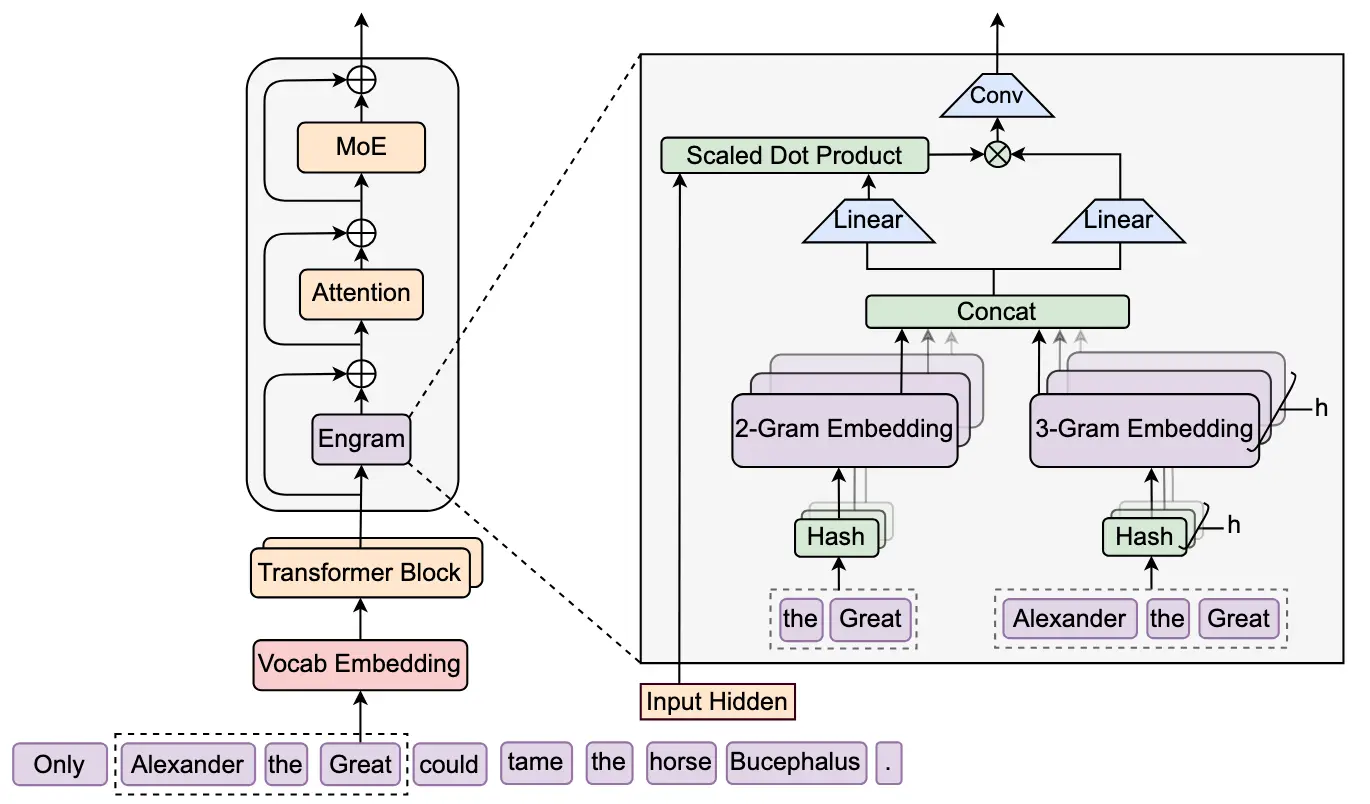
告别 GPU 算力浪费!DeepSeek 条件记忆技术:让大模型检索静态知识更高效
当企业级大语言模型(LLM)在回答“iPhone 15 的电池容量是多少?”或“标准 NDA 条款包含哪些内容?”这类问题时,它正在动用为复杂推理设计的昂贵 GPU 计算资源——仅仅为了检索一段静态信...

告别命令行!Anthropic发布Cowork:解锁Claude智能体新玩法,非开发者也能轻松上手
Anthropic 正式推出一款名为 Cowork 的全新工具,该工具作为 Claude Code 的简化易用版本,内置在 Claude 桌面应用中,核心优势在于无需用户掌握编程技能,就能借助 Cla...

苹果谷歌官宣合作:Gemini将为Siri及Apple Intelligence提供底层AI支持
苹果与谷歌正式官宣达成多年期合作协议,苹果将采用谷歌的Gemini模型及云技术构建下一代基础模型,为Siri语音助手及Apple Intelligence相关功能提供底层支撑。这一合作是苹果在AI领域...





