新型多模态原生模型Aria:专门设计来处理和理解多种类型的信息(文本、代码、图像和视频)Rhymes AI推出新型多模态原生模型Aria,这是一个开源的混合专家(MoE)模型,ARIA专门设计来处理和理解多种类型的信息,比如文本、代码、图像和视频,而且它能够像人类一样,不需要特别区分这些...多模态模型# Aria# Rhymes AI# 多模态模型1年前05510
大型多模态模型LLaVA-Video:专门设计来处理视频指令并进行视频内容理解字节跳动、南洋理工大学S-Lab和北京邮电大学的研究人员推出大型多模态模型LLaVA-Video,专门设计来处理视频指令并进行视频内容理解。这个模型特别擅长于解析和生成与视频内容相关的语言描述,比如详...多模态模型# LLaVA-Video# 多模态模型1年前05620
新型开源大型多模态模型LLaVA-Critic:用于评估各种多模态任务的性能字节跳动和马里兰大学帕克分校的研究人员推出新型开源大型多模态模型LLaVA-Critic,它被设计成一个全能的评估者,用于评估各种多模态任务的性能。多模态任务通常涉及理解和生成与图像、视频和文本相关的...多模态模型# LLaVA-Critic# 多模态模型1年前04440
新型CLIP专家混合模型CLIP-MoE:可以无缝替换CLIP,以即插即用的方式,而无需在下游框架中进一步适应香港中文大学、上海人工智能实验室和舒尔茨大学的研究人员推出新型CLIP模型CLIP-MoE,它是为了增强现有的多模态智能模型CLIP而设计的。CLIP-MoE可以无缝替换CLIP,以即插即用的方式,而...多模态模型# CLIP-MoE# 多模态智能模型1年前05890
智源研究院推出全新多模态系列模型Emu3智源研究院推出Emu3,这是一个全新的多模态系列模型,它仅使用下一个词元(Token)预测这一建模范式进行训练,达到了最先进的水平。Emu3 通过一个 Transformer 模型在视频、图像和文本令...多模态模型# Emu3# 多模态模型# 智源研究院1年前04240
Meta发布 Llama 3.2 模型:从 轻量级纯文本模型(1B 和 3B)到 中小型多模态模型(11B 和 90B)Meta于9月25日正式推出了Llama 3.2模型,这款新模型以其开放性和可定制性为特点,旨在满足开发者在边缘人工智能和视觉处理领域的多样化需求。Llama 3.2 结合了多模态视觉能力和轻量化设计...多模态模型# Llama 3.2# Meta1年前04200
新型多模态模型家族Molmo:专门设计用于理解和处理图像和文本数据华盛顿大学和艾伦人工智能研究所的研究人员推出新型多模态模型家族Molmo,这些模型专门设计用于理解和处理图像和文本数据。Molmo的目标是提供一个最先进的、开放的多模态模型,Molmo的关键创新是一个...多模态模型# Molmo# 多模态模型1年前04570
多模态大语言模型Qwen2-VL-7B-Captioner-Relaxed:经过指令调整的Qwen2-VL-7B-Instruct版本Qwen2-VL-7B-Captioner-Relaxed 是 Qwen2-VL-7B-Instruct 的一个经过指令调整的版本,它是一个多模态大语言模型。这个经过精细调整的版本是基于一个为文生图模...多模态模型# Qwen2-VL-7B-Captioner-Relaxed# 多模态大语言模型1年前05730
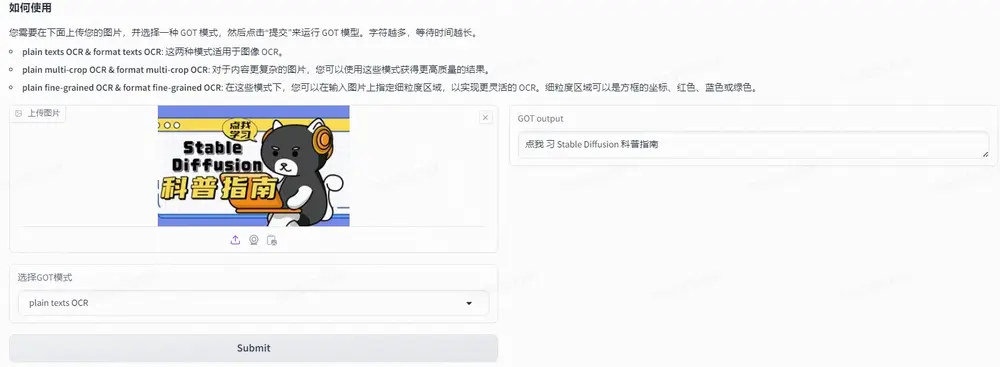
GOT-OCR-2.0模型:专为识别和处理各种字符而设计的OCR模型GOT-OCR 模型是一个参数量达 580M 的OCR系统,专为识别和处理各种字符而设计。该模型配备了高压缩编码器和长上下文解码器,能够精准处理各种场景和文档风格的图像。它支持多页和动态分辨率的 OC...多模态模型# GOT-OCR-2.0# OCR模型1年前04620
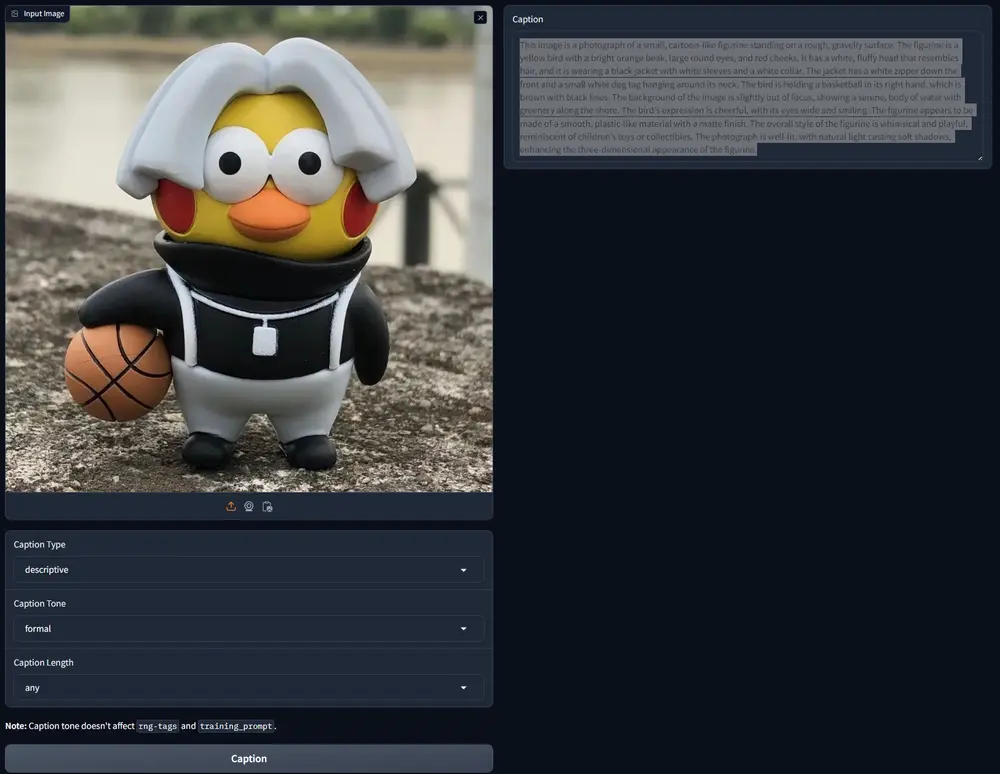
JoyCaption:从零开始构建的免费、开放且未经审查的视觉语言模型JoyCaption,一个从零开始构建的免费、开放且未经审查的视觉语言模型(VLM),旨在助力社区训练SD或Flux模型。它不仅免费开放,还提供训练脚本和丰富的构建细节,就像bigASP一样。 Dem...多模态模型# JoyCaption# 视觉语言模型1年前05380
新型目标检测模型Mamba-YOLO-World:能够理解并识别各种不同物体的智能系统,即使这些物体在训练时没有被明确标记复旦大学计算机学院、腾讯优图实验室、上海交通大学等的研究人体推出新型目标检测模型Mamba-YOLO-World,它专门设计用于开放词汇检测(Open-Vocabulary Detection,简称O...多模态模型# Mamba-YOLO-World# 目标检测模型1年前06770
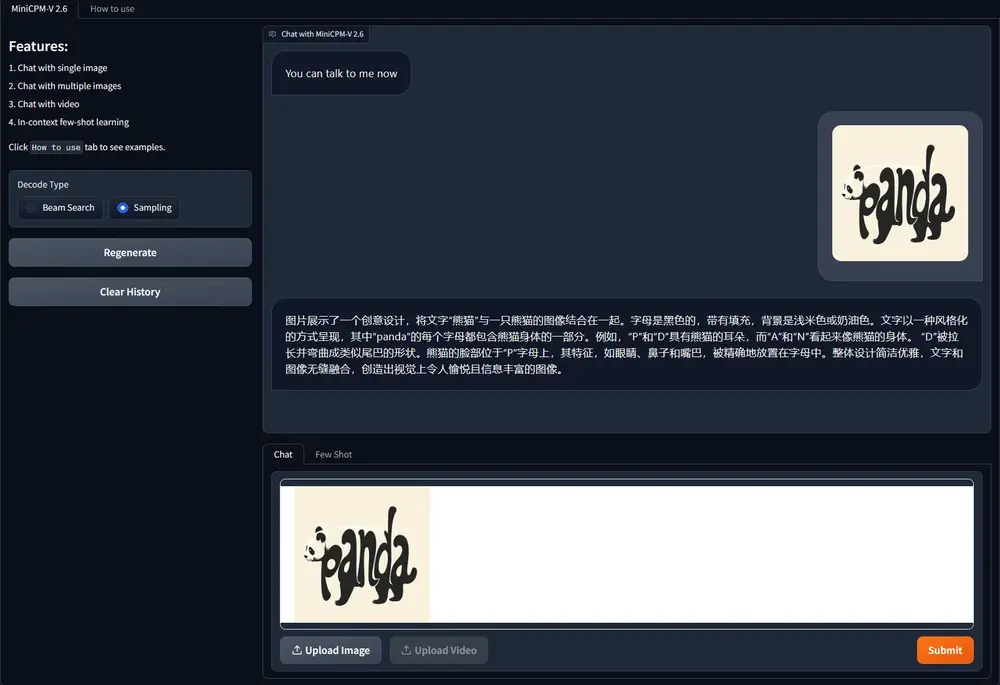
面壁智能推出开源多模态大语言模型MiniCPM-V 2.6:可以在手机上运行与GPT-4V水平相当的任务面壁智能昨日开源了 MiniCPM-V 2.6 模型,官方表示将端侧 AI 多模态能力拉升至全面对标 GPT-4V 水平。MiniCPM-V是面向图文理解的端侧多模态大模型系列。该系列模型接受图像和文...多模态模型# MiniCPM-V 2.6# 面壁智能1年前05350